Clockwork FleetIQ Platform
Nano-second Accurate Visibility Correlated Across the Stack
AI at scale slows when GPU, cluster, or cloud communication falters. FleetIQ unifies nanosecond-level visibility, dynamic traffic control, and job-aware resilience in one software control plane — transforming communication into a performance lever. The result: fewer restarts, faster training, true operating capacity.
3 Dysfunctions AI Infrastructure Teams Grapple With
Dysfunctional networks hurt GPU Utilization,
Job Completion Time, overall ROI



AI Fabrics Are Different
LLM Training Patterns vs. Traditional Cloud Computing
Source: Alibaba HPN – A Data Center Network for large Language Model Training ACM SIGCOMM ‘24, August 4-8, 2024, Sydney, NSW, Australia
-
Separate back-end and front-end networks
-
Highly demanding back-end network:
Lossless | Very high-bandwidth | Low latency and jitter | In-order delivery -
Frequent network failures due to optical port density, overheating, dust, etc.
A Fabric Built for AI at Scale
Clockwork Frees AI from Communication Constraints
Clockwork FleetIQ transforms AI infrastructure by unifying nanosecond visibility, job-aware resilience, and dynamic traffic control into one software-driven AI fabric. Unlike static, vendor-bound networks, FleetIQ runs anywhere—across GPUs, NICs, switches, and transports—normalizing performance and accelerating training without application changes
From Precision to Control: End-to-End Fabric Intelligence
Transform AI fabrics into resilient, high-performance networks
Clockwork FleetIQ Platform Foundation: Global ClockSync
Sub-microsecond accurate visibility
Global ClockSync aligns every host, NIC, and switch to a shared sub-microsecond timeline. This unified clock enables precise telemetry and real-time correlation across jobs, GPUs, and networks—turning invisible slowdowns into observable, actionable data.
Delivers Nanosecond Telemetry, Unified Time Sync
and Precise Root-Cause Attribution.
Clockwork’s NCCL Plugin
Provides Granular Fleet & AI Job Visibility
Supports RoCE and InfiniBand
Dynamic Traffic Control (DTC) actively steers flows to avoid collisions and incast collapse. By pacing queue pairs and shifting traffic across underutilized paths, DTC bounds tail latencies and keeps synchronized collectives moving forward.
Delivers Network Auto-failover, Congestion Control and Load Balancing
Addressing the Visibility Gap: Clockwork Fleet Audit,
Fleet Monitoring, Workload Monitoring
From clean starts to continuous uptime: end-to-end AI fleet assurance
Deploy a reproducible, known good baseline fleet to run AI workloads
Keep the fleet healthy, performant and cost-effective while AI jobs run
Fleet Audit
- Software checks
- Node checks
- Front-end network
- Back-end GPU network validation
Fleet Monitoring
- Runtime link failures/flaps
- Runtime fabric topology
- Runtime fabric performance
- Congestion and contention monitoring
Workload Monitoring
- Deep workload visibility
- Correlation of data path performance with network metrics to identify root cause of job performance
Clocksync Foundation
- Deep workload visibility
- Correlation of data path performance with network metrics to identify root cause of job performance
Disruptive Network Failures and Link Flaps
Are Common and Expensive
Failures Happen Frequently—Even in Brand New Clusters
One of the most common problems encountered is Infiniband/RoCE link failure. Even if each NIC-to-leaf switch link had a mean to failure rate of 5 years, due to the high number of transceivers, it would only take 26.28 minutes for the first job failure.

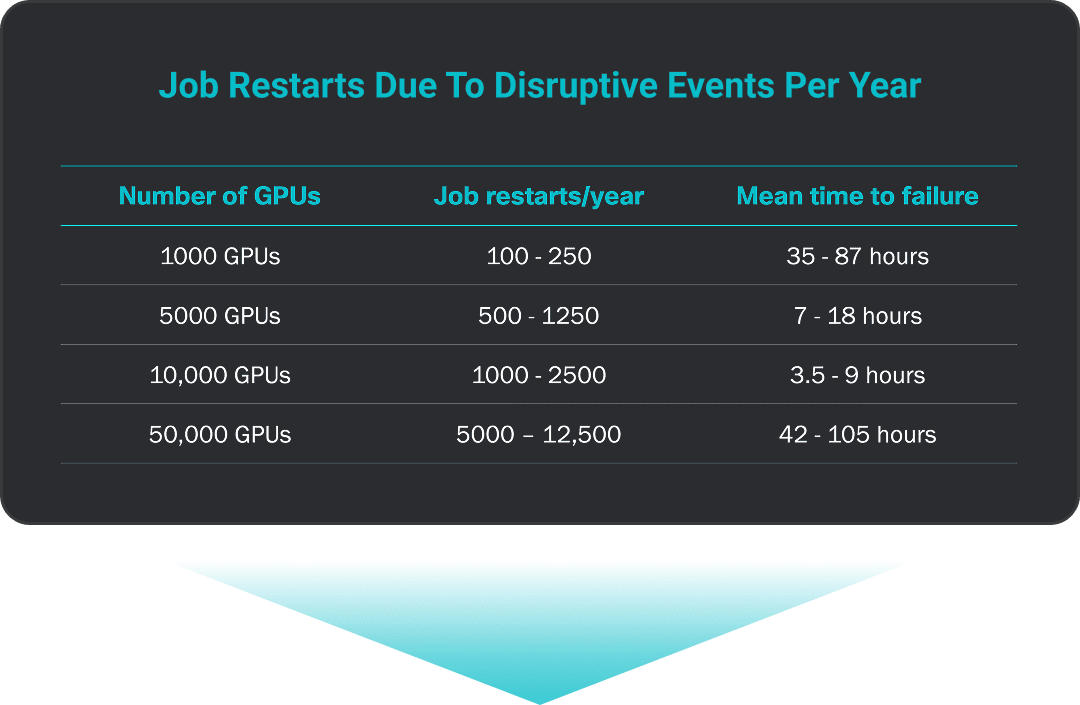
“Achieving high utilization with them (GPUs) is difficult due to the high failure rate of various components, especially networking.
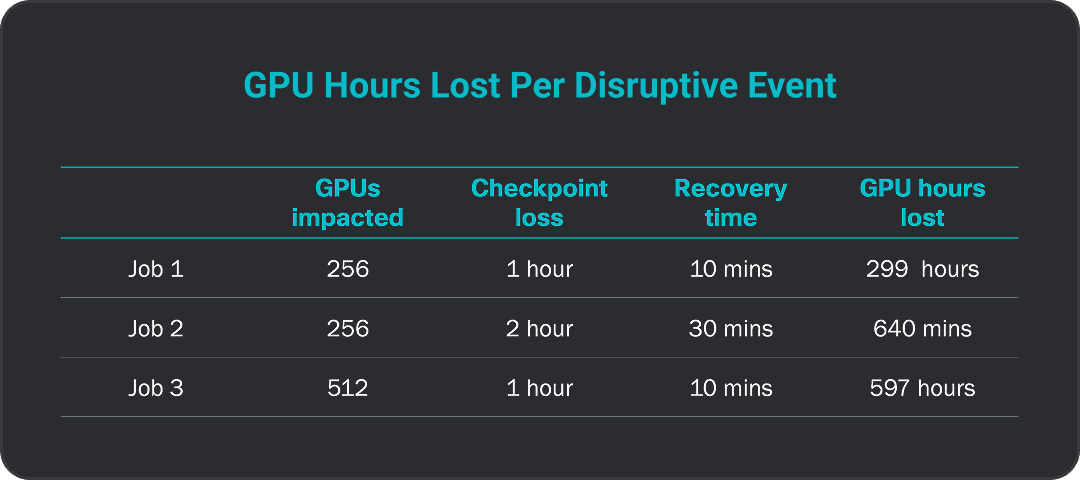
lost per incident
Source: Falcon: Pinpointing and Mitigating Stragglers for Large-Scale Hybrid-Parallel Training, 2024; The Llama 3 Herd of Models, 2024; “Alibaba HPN: A Data Center Network for Large Language Model Training”, ACM SIGCOMM ’24; Gemini: Fast Failure Recovery in Distributed Training with In-Memory Checkpoints, 2023
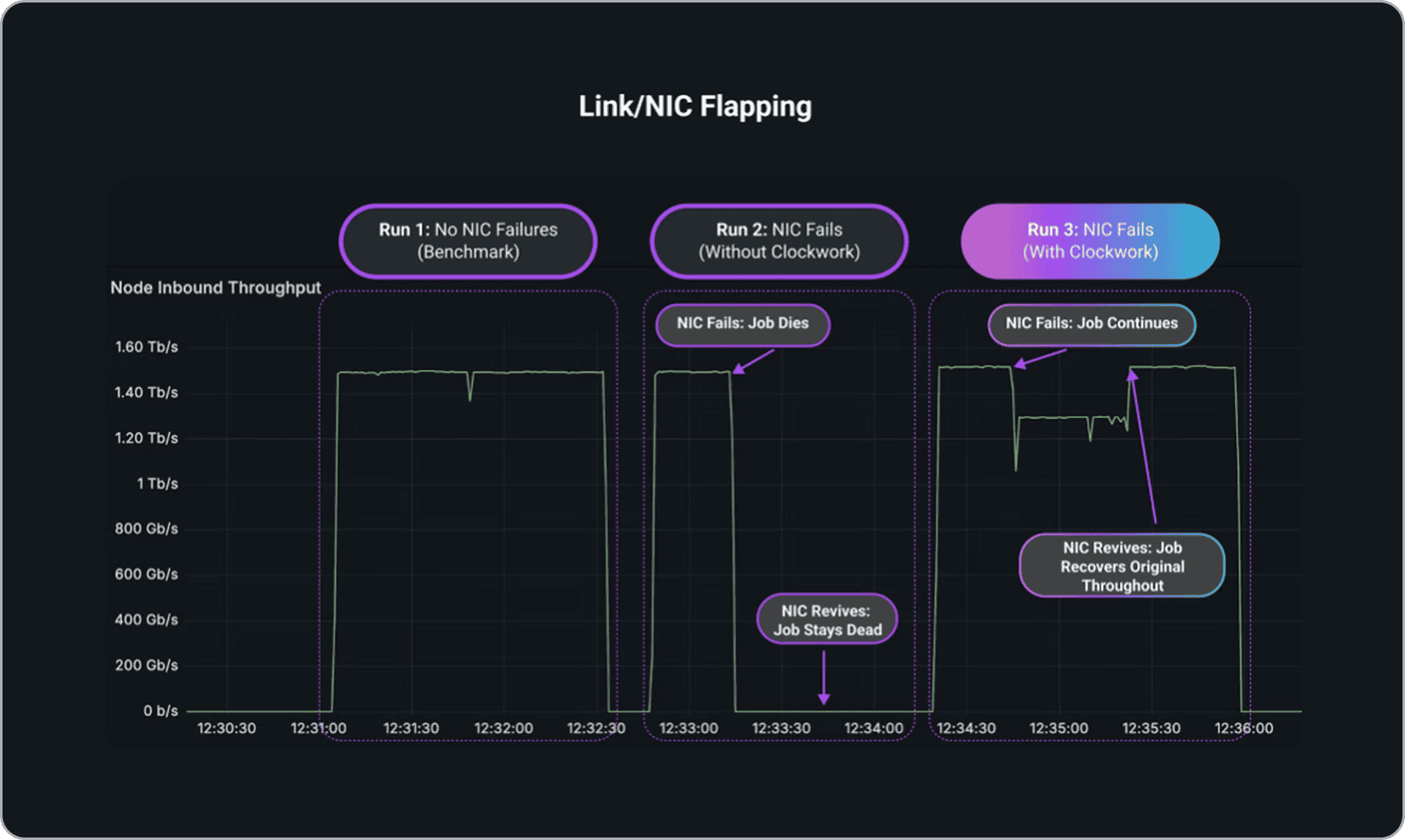
Link / NIC Flapping: Before And After Clockwork.
Without Clockwork, a NIC failure halts AI jobs entirely. With Clockwork, jobs continue at reduced throughput during a failure and quickly return to full capacity, ensuring robust resilience and uninterrupted performance
Workload Acceleration
Proven Throughput Gains Across Real-World AI Workloads
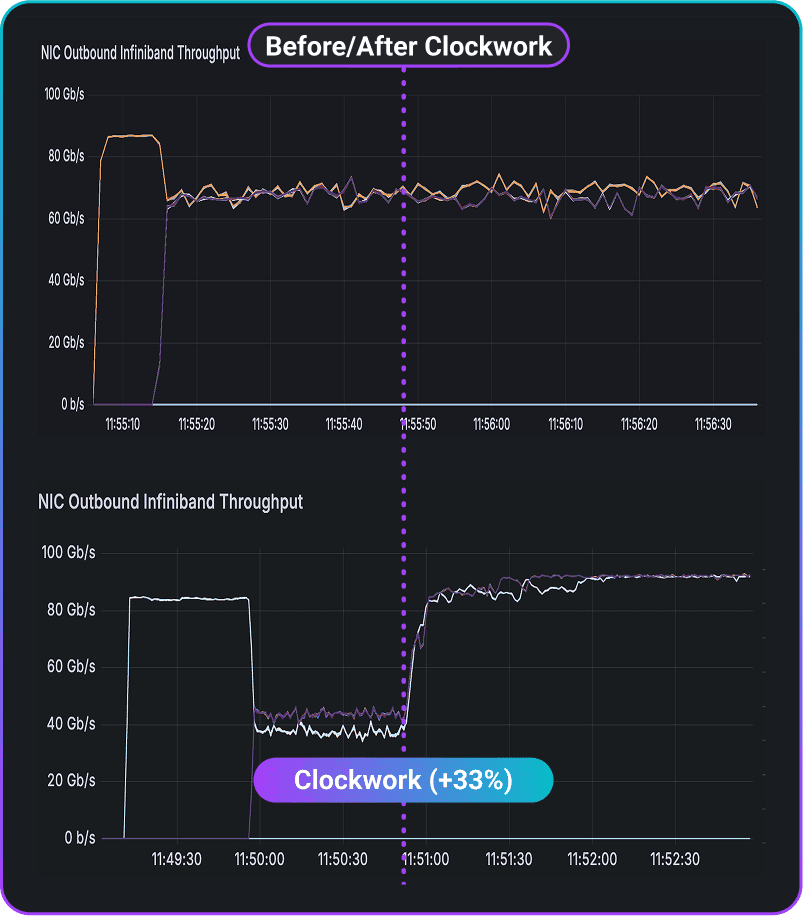
Hyperscaler with Clockwork vs Dynamic Load Balancing (DLB)
2 all-to-all jobs
The hyperscaler with Clockwork enabled has 33% more outbound throughput vs. DLB
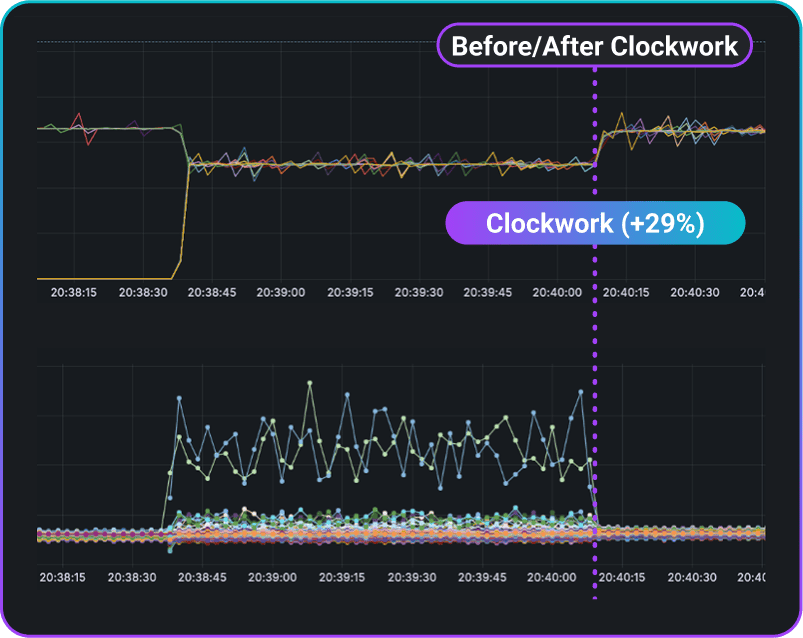
Large Social Media Company with Clockwork vs. ECMP
2 all-to-all jobs
The large social media company with Clockwork enabled has 29% more throughput vs. ECMP
Learn More
Stop wasting GPU cycles. Start scaling smarter.
Clusters must deliver high uptime while running at maximum efficiency.
Turn your GPU clusters into a competitive advantage—not a cost center.
