TorchPass Workload Fault Tolerance
Introducing TorchPass Live GPU migration. Training never stops!
Distributed AI training is notoriously fragile and unreliable. Even a single link flap or GPU fault can crash an entire long-running job. Each time this happens, hours of training are lost because recovery requires restarting from the most recent checkpoint.
TorchPass Workload Fault Tolerance prevents failures from impacting training jobs by performing a live GPU migration to spare resources.
Software Driven AI Fabrics Drive
Peak Cluster Utilization
* Assumes 1.5 hour checkpoint frequency, 15 minutes training restart time and 7.9 hour MTTF based on Meta Fair research: https://arxiv.org/pdf/2410.21680
“Managing compute output across large-scale GPU clusters is vital to ensuring we’re delivering reliable capacity to our customers. By using TorchPass we have the support of a company that focuses on resilience like it is a core business function: it replaces any specific failing GPU and keeps the rest of the job moving, rather than making one small problem impact our large-scale operations. In our evaluation, Live GPU Migration preserved both run continuity and throughput under real fault conditions, which is exactly what you need to deliver predictable time-to-train and a better customer experience at scale.”
Ship models faster
Eliminate hours lost to training failures
Link flaps, GPU faults, driver/firmware bugs and even full node failures no longer crash jobs. TorchPass Workload Fault tolerance reroutes traffic around network problems and performs live GPU migration onto spare resources when things break. All of this is done without disruption to distributed training.
Enable Zero-downtime Maintenance
Critical infrastructure tasks like security patching, firmware updates, workload rebalancing, and dealing with straggler nodes typically require stopping long-running training jobs. With TorchPass, entire nodes can be transparently swapped out so maintenance can occur while training continues uninterrupted.
Runs Anywhere
TorchPass is 100% software-based, runs anywhere and supports popular training frameworks and schedulers including TorchTitan, Megatron-LM, DeepSpeed, Slurm and Kubernetes.
Increase GPU ROI
Eliminate costly checkpoint restarts and hours of lost progress
When training fails, the standard recovery method is to restart from the most recent checkpoint. This not only wastes time during restore and restart but also means work since the last checkpoint must be recomputed. TorchPass eliminates this waste by performing live GPU migration, eliminating the need for costly checkpoint restarts.
Avoids idle GPUs and minimizes the blast radius
TorchPass treats individual components (down to a single GPU) as the failure domain dramatically reducing the blast radius of interruptions. Dedicated spares do not have to sit idle, instead TorchPass dynamically draws replacement capacity from any available resources or even reclaims them from lower priority jobs.
Reduce checkpoint overhead during run time
Choosing how frequently to take checkpoints used to be a compromise between checkpoint overhead and the risk of losing work after failures. TorchPass removes this tradeoff by handling common failures transparently, allowing you to safely take checkpoints less frequently, with less overhead.
“In our testing, Clockwork.io TorchPass delivered the fastest and most efficient fault-tolerant performance for a gpt-oss-120B training run. We used TorchTitan on a Kubernetes cluster with 64x H200 GPUs. During our testing we measured job completion time (JCT) and Model FLOPs Utilization (MFU) against a standard approach (checkpoint-restart) and the leading open-source fault-tolerant training framework (TorchFT). We simulated multiple hardware failures on the cluster in order to stress test the fault-tolerant training frameworks.
When compared to checkpoint-restart, TorchPass was significantly faster to recover from failures. This reduced overall JCT and maintained high MFU. And when compared to TorchFT, TorchPass had a significantly higher MFU. This reduced overall JCT while also maintaining an equal time to recover from failures.
Using TorchPass also has a downstream effect where it provides users with an opportunity to reduce or even remove checkpointing from their training code. This means larger effective batch sizes, lower risk of out of memory errors (OOMs), and less time spent thinking about storage. For a research organization, this can ultimately mean a faster time to reach their training objective.”
Accelerate the Transition to Rackscale Systems
Unlock best-in-class performance and energy efficiency
NVIDIA’s latest NVL72 GB200/GB300 configurations and upcoming Vera Rubin NVL144 systems deliver industry-leading energy efficiency and performance per dollar. However, their dense, tightly coupled architectures amplify the impact of small failures on distributed training workloads. TorchPass makes reliability a software-defined property, enabling safe deployment and maximized ROI of rackscale systems without compromising training reliability.
Increase GPU utilization by reducing spare overhead
NVL72 systems are typically configured with 16 active and two spare trays, since a component failure often requires replacing an entire tray and restarting the training job. TorchPass enables GPU-level failover, eliminating the need to swap whole trays on failure. This allows operation with a single spare tray while still tolerating multiple component failures during training.
“As Blackwell clusters roll out with an NVL72 domain, and we look to the future with Rubin Ultra’s NVL576 domain, the idea that a single GPU error or network link flap can take down an entire run is totally unacceptable. TorchPass solves a huge challenge with cluster reliability: it provides transparent failover and live workload migration that keeps MFU high, which in turn drives better GPU economics.”
Network Fault Tolerance
Link flaps and network faults no longer crash jobs. Instead, they are handled seamlessly by rerouting affected traffic onto alternative paths.
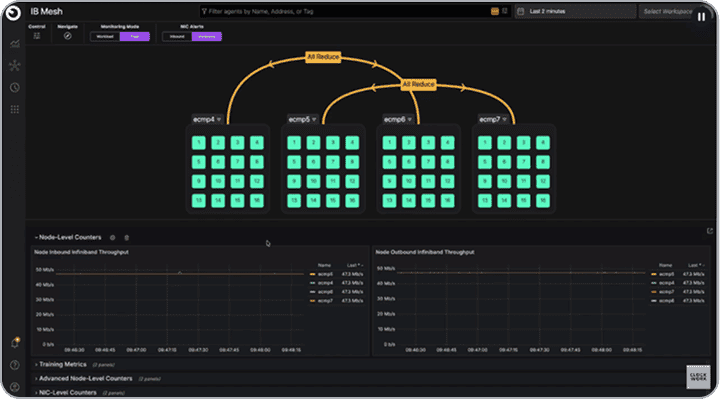
The Magic Happens by Using a Lightweight NCCL Plugin
A Comparison of Link Failures With and Without Clockwork

Network fault tolerance is powered by a lightweight NCCL net plugin that takes less than a minute to install. When a network issue is detected, the NCCL plugin reroutes the affected job to one or more alternative NICs.
It continuously monitors the original NIC and automatically restores the job to its original path if the NIC comes back online. If the issue persists, the job can be transparently migrated to a spare GPU to provide full network bandwidth.
Contact Us For a Free Trial
See how easy it is to keep your jobs running even when the network is unstable.
Live GPU Migration
GPU memory errors, GPUs falling off the bus, driver or firmware bugs, and even full node failures are now handled without disrupting distributed training.
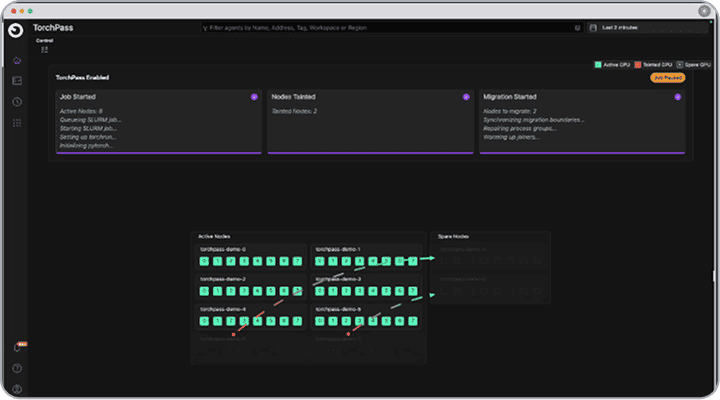
Under the Covers, TorchPass Is Made Up Of
Two Primary Components
TorchPass Orchestrator
The orchestrator is the central brain that communicates with the TorchPass scheduler plugin to track jobs and spare resources. It manages the migration process when a failure (planned or unplanned) occurs.

TorchPass Scheduler Plugin
The Scheduler plugin acts as an adapter between the TorchPass Orchestrator and the cluster’s native scheduler (e.g. Kubernetes or Slurm) API.
The Migration Process
When a node or GPU in a distributed training job fails, the orchestrator schedules the migration of the failed resource to a spare resource.

Work pauses briefly while migration occurs. Once complete, the Scheduler Plugin updates the cluster scheduler to reflect the swap and training resumes from the exact failed step, as if nothing happened.

Contact Us For a Free Trial
See how easy it is to keep your training jobs running through any kind of failure. Our team will help you get up and running quickly so you can experience live GPU migration in your own environment. Say goodbye to costly checkpoint restarts!
Learn More
Stop wasting GPU cycles. Start scaling smarter.
Clusters must deliver high uptime while running at maximum efficiency.
Turn your GPU clusters into a competitive advantage—not a cost center.
