Maximize Model Uptime and
Accelerate Time-to-Market
Keep training jobs alive and models moving to market faster
- Clockwork ensures your AI jobs don’t crash when infrastructure falters.
- Nano-second precise monitoring, auto-remediation and sub-microsecond stateful job failover combine to keep workloads progressing without costly restarts.
The result: higher model uptime, faster time-to-train, and quicker paths to production
Maximize AI Model Uptime
Prevent AI Job Interruptions
Preempt interruptions before they stall progress
Minimize checkpoints. Maximize uptime. Accelerate results. Traditional clusters restart more, checkpoint more, and deliver less. With Clockwork, preemptive fault tolerance keeps training and inference jobs running without constant interruptions. Reduce restarts, cut wasted checkpoint time from hours to minutes, and accelerate time-to-market for large models.
Stop Wasting GPU Cycles
On Network Communication Inefficiency
Turn idle communication time into productive compute.
Source: AMD
Up to 40% of cluster time can be lost to communication bottlenecks — leaving GPUs idle while workloads wait. Intelligent traffic routing keeps compute flowing, boosting utilization, throughput, and ROI from every GPU hour.
Close the AI Efficiency Gap By Maximizing GPU Utilization
Identify cluster inefficiencies in real-time
Pinpoint inefficiencies with nanosecond precision. Fix them in real time.
Crash-Proof AI Jobs.
Trace. Correlate. Optimize — across every layer
Supercharge cluster utilization and customer innovation
-
Avoid job crashes from GPUs falling off the bus to NIC failures or timeouts from link flaps or dust particles
-
Dramatically reduce checkpoint recoveries
-
Accelerate experiments and time-to-market
From NIC failures to GPU drop-offs, Clockwork detects issues in nanoseconds and re-routes workloads in real time. Dynamic traffic control ensures uninterrupted performance — enabling stateful fault tolerance that keeps massive AI jobs running non-stop.
Bulletproof Jobs With One Pane of Glass.
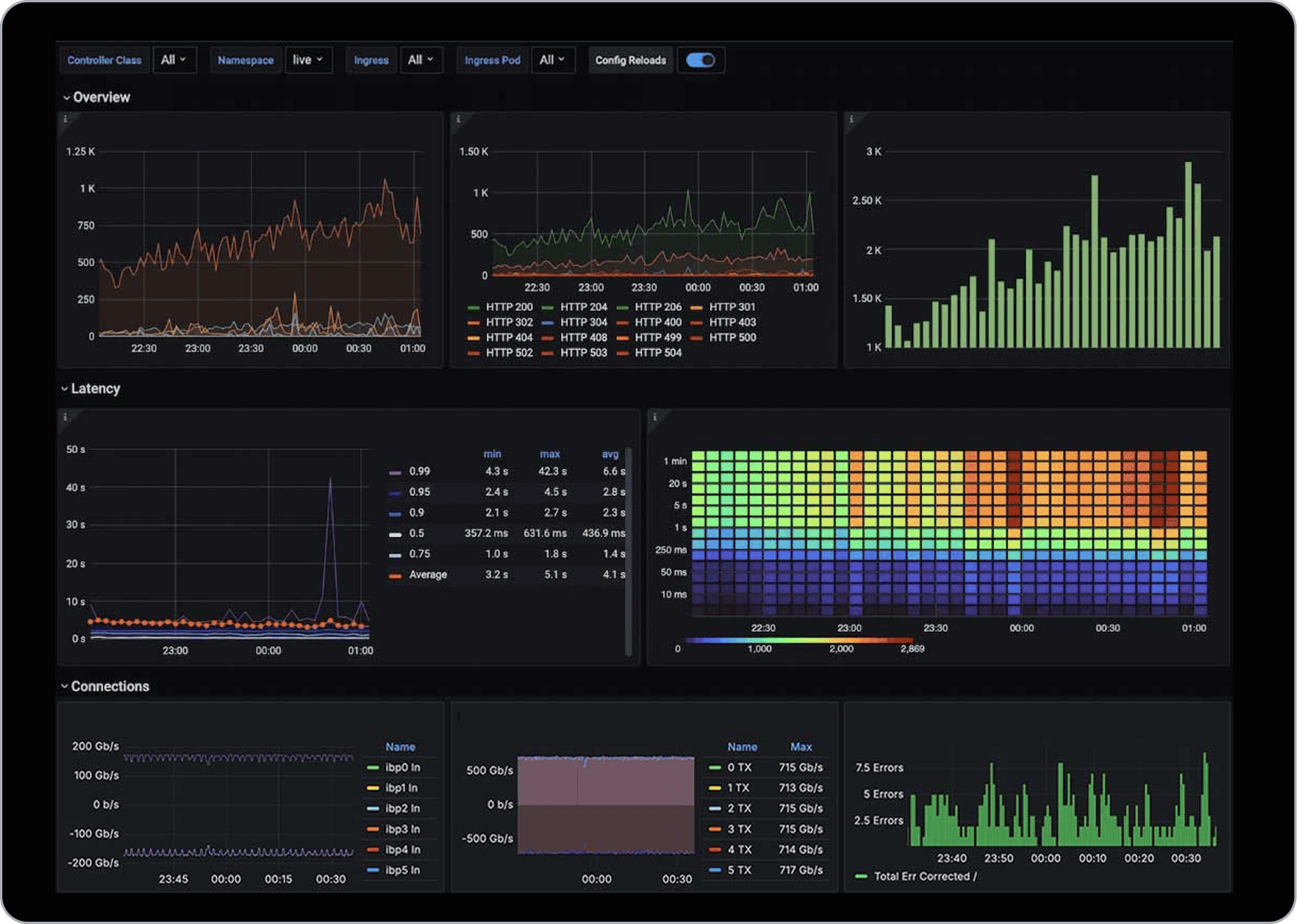
Integrate Clockwork cross-stack metrics into Grafana Dashboards
Clockwork provides fine-grained, cross-stack observability with API-level access to integrate with your existing Grafana dashboards. Monitor workloads, correlate performance with fabric metrics, and trace bottlenecks with nanosecond precision. Finally, one pane of glass for compute, storage, and networking.
Single Pane of Glass Grafana Dashboards
Accelerate Time-to-Value. Every Time. At Any Scale.
Deliver consistent performance from fleet audit to runtime.
Clockwork validates and audits fleets on Day 1, then proactively remediates runtime issues with sub-microsecond response. Continuous performance monitoring ensures workloads maintain consistent SLA targets while cutting operational overhead. Faster deployments. More resilient fleets. Lower costs. Communicate
Deploy a consistent & reproducible good baseline fleet to run AI workloads
Run continuosly performant AI workloads with stateful fault tolerance and a more cost-effective fleet operations
Fleet Audit
- Software checks
- Node checks
- Front-end network
- Back-end GPU network validation
Fleet Monitoring
- Runtime link failures/flaps
- Runtime fabric topology
- Runtime fabric performance
- Congestion and contention monitoring
Workload Monitoring
- Deep workload visibility
- Correlation of data path performance with network metrics to identify root cause of job performance
Deliver Faster AI Jobs, Better Cluster Up-time and Hardware Independence
Maximize cluster utilization with more concurrent AI jobs
Clockwork eliminates AI job contention with advanced flow control, enabling more concurrent jobs, higher utilization, and greater uptime. Higher utilization means lower compute costs and faster training cycles. Clockwork achieves this by classifying flows at the source, using sub-microsecond telemetry to steer around hot paths, pacing background traffic, and admitting or deferring work to protect priority jobs.
Software-Driven Fabric creates a unified software control plane
Clockwork’s Software-Driven Fabric (SDF) is the architectural foundation of the solution — an intelligent, nanosecond precise unified software control plane that statefully orchestrates all traffic, sustains high cluster utilization, accelerates time-to-train, and makes large AI fleets economically scalable.


Increase customer choice and investment protection with 100% Software Driven AI Fabrics
AI factories are inherently heterogeneous — with diverse GPUs, NICs, switches, transports, and APIs. Vendor-specific optimizations may deliver short-term gains, but they create brittle fabrics and lock customers into costly refresh cycles.
Clockwork’s Software-Driven Fabric (SDF) provides a unified software control plane: any GPU, any NIC, any switch, any transport. By normalizing vendor and generational differences, SDF delivers consistent visibility, real-time control, and fault tolerance across InfiniBand, Ethernet, and RoCE — without application changes.
The result: true hardware independence, faster adoption of new technologies, and protection of past investments. With Clockwork, every GPU hour counts toward customer value.
Learn More
Stop wasting GPU cycles. Start scaling smarter.
Clusters must deliver high uptime while running at maximum efficiency.
Turn your GPU clusters into a competitive advantage—not a cost center.