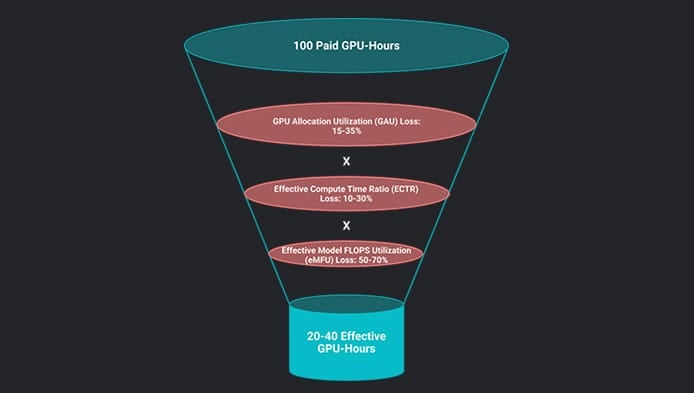
TL;DR
The data center is undergoing a fundamental architectural discontinuity, moving from loosely coupled, independent request handling to Tightly-Coupled Synchronized Clusters for large-scale AI training and distributed inference. This new design requires thousands of processors to execute in coordinated lockstep, making the entire system highly sensitive to the “straggler effect” and acute failure, demanding new disciplines in networking, storage, and topology-aware scheduling
From Independent Requests to Collective Computation
For two decades, data center infrastructure relied on the principle of individual, stateless, loosely coupled requests. This design—where each transaction is self-contained and failures are routed around—created elastic, horizontally scalable, and forgiving systems. The next step in this evolution introduced chained service graphs (microservices), which were more demanding but still tolerant due to mechanisms like retries and auto-scalers.
But the rise of large-scale AI is driving a fundamental architectural discontinuity. We have arrived at the era of Tightly-Coupled Synchronized Clusters. This new contract demands that hundreds or thousands of processors execute in coordinated lockstep, exchanging vast quantities of data at every step. There is no graceful degradation: the entire system moves at the speed of its slowest participant, and a single failure can halt the work of thousands of processors.Comparing the Three Eras of Infrastructure Design
This shift from independent to collective computation represents a change in the core infrastructure contract:
Three eras at a glance
| Characteristic | Loosely Coupled | Service Graphs | Synchronized Clusters |
| Progress Model | Independent | Sequential chains | Lock-step; straggler gated |
| Failure impact | Isolated; Routed around | Partial; mitigated by retries | Global; entire job at risk |
| Placement | Location-transparent | Proximity helps | Topology-critical |
| Network role | Utility interconnect | Important but secondary | First-class compute resource |
| Storage I/O | Independent, transactional I/O | High concurrency; heavy caching | Massive, synchronized bursts |
- Key Workloads Driving the Need for Tightly-Coupled Infrastructure
While the table above describes the shift in abstract terms, three workload families are practically driving the transition to tightly-coupled infrastructure today, each sharing the same core infrastructure contract: coordinated progress, shared fate on failure, collective communication, and sensitivity to physical topology.
AI Training
-
- The Canonical Example: Large language model training runs distribute a single mathematical optimization across hundreds or thousands of GPUs, which must synchronize after every forward and backward pass.
- Impact: This workload is profoundly affected by the straggler effect at every step. Failure sensitivity is acute due to long-lived distributed state (accumulated model state that is expensive to lose and checkpoint), and collective communication dominates the network profile.
- Infrastructure Stress: Checkpoint writes create the defining storage I/O burst, and placement determines whether communication traverses fast local links or congested uplinks.
Distributed Inference
-
- Growing Complexity: As models grow beyond a single GPU, serving a request requires splitting the model across GPUs and even across nodes.
- Stateful Nature: The KV cache is per-request state that accelerates token generation, making these workloads stateful in ways traditional stateless serving was not. Losing a node means losing cached state for every active request on that shard.
- Cost Sensitivity: Latency sensitivity is tighter than training since users are waiting in real time. This converges infrastructure demands toward training’s requirements, such as placement-aware scheduling and low-jitter fabric performance.
Scale-out Storage
-
- Tightly-Coupled Operations: High-performance distributed file systems and object stores exhibit tightly-coupled behavior during critical operations like Erasure Coding and Parity Reconstruction during a node failure. These are collective patterns that enforce synchronization barriers analogous to training’s all-reduce.
- Critical Path Impact: Because these storage systems serve as the checkpoint target for training and the model-loading tier for inference, their I/O performance sits directly on the critical path of GPU workloads. A storage system that cannot absorb a synchronized checkpoint write becomes the straggler for the entire training job.
2.The Four Defining Characteristics of Synchronized Clusters
Each of these four characteristics represents a design constraint, the violation of which results not just in reduced performance but in catastrophic inefficiency—idle GPUs burning power without producing useful work.
2.1. Stateful Execution and Acute Failure Sensitivity
The traditional “cattle, not pets” philosophy is entirely inverted in tightly-coupled workloads.
-
- State Accumulation: Each GPU holds a portion of accumulated model state (parameters, gradient accumulators), representing hours of computation.
- Shared Fate: When a single GPU or network link fails, the entire job must typically halt and roll back to the last checkpoint.
- Inference Risk: In large-model inference, losing a single node invalidates the distributed KV cache for every active request on that shard, forcing a full recomputation of the cache or a degraded serving mode.
2.2. Topology-Aware and Placement-Sensitive
Tightly-coupled workloads shatter the abstraction of location transparency promised by cloud computing.
-
- Performance Disparity: Communication speeds vary drastically: GPU-to-GPU within a node over NVSwitch runs at ~900 GB/s with sub-microsecond latency, while communication across nodes via the external fabric is slower, ranging from 50 – 400 GB/s with meaningfully higher latency.
- Locality Matters: Two clusters with identical nominal network speeds can deliver different throughput based on whether one preserves locality, ensuring more pairs communicate on fast local links.
- Scheduling Requirement: Job schedulers must become topology-aware, solving an optimization problem over the physical topology graph rather than simply finding available resources.
2.3. The Network Is A First-Class Compute Co-Processor
In synchronized clusters, the network is no longer just “plumbing”—it participates in the computation itself.
-
- Efficiency Impact: Every millisecond a GPU waits for the network is a millisecond it is not computing, leading to enormous financial loss on large clusters if scaling efficiency is poor (e.g., doubling GPUs yields only 1.6X speedup).
- Traffic Profile: The traffic pattern is not point-to-point but collective and simultaneous. This makes bisection bandwidth and fabric-wide congestion behavior critical.
- Validation: Leading designs now specify and validate network bandwidth, latency, and jitter as precisely as GPU FLOPS, treating the fabric as a co-processor.
2.4. High-Throughput, Bursty Storage I/O on the Critical Path
The storage tier faces a brutal pattern of massive, synchronized bursts, distinct from traditional storage I/O.
-
- The Checkpointing Cliff: During a checkpoint, thousands of GPUs must write out a multi-terabyte snapshot of the full distributed state all at the same instant.
- Straggler Risk: If the storage tier cannot absorb this synchronized write, every processor sits idle waiting for the I/O to complete—the storage system becomes the straggler for the entire training job.
- Data Ingestion: Continuous high-throughput reads from a parallel file system are also required for data ingestion, where any stall risks starving GPUs between steps.
- Demand: This profile—continuous high-bandwidth reads punctuated by massive synchronized write cliffs—demands purpose-built parallel file systems and high-performance storage fabrics.
3. The New Infrastructure Discipline: Engineering the Modern Data Center
The traditional design principles of cloud computing—statelessness, horizontal elasticity, location transparency, and tolerance of individual failure—are often directly counterproductive for tightly-coupled workloads.
We are shifting from infrastructure optimized for independent request handling to infrastructure optimized for coordinated completion of shared phases across many devices.
This shift demands:
-
- Predictable performance over peak performance.
- Failure domain engineering over simple redundancy.
- Fabric-first networking and placement-aware scheduling.
- Storage architectures designed for synchronized I/O bursts.
The data center is not just getting bigger; it is getting fundamentally more tightly coupled, more synchronous, and more demanding. Surviving this inflection point requires a fundamental architectural shift where intelligent software controls and physical network fabrics are engineered as one.