Global ClockSync for Sub-Microsecond-Granular Telemetry
Software-based precision telemetry tracing AI workloads fleet-wide
Breakthrough: High Accuracy ClockSync at Scale
Traditional time-sync solutions like NTP and PTP weren’t built for the demands of modern AI infrastructure. NTP lacks fine-grained accuracy, while PTP introduces complexity, master-slave bottlenecks, and poor scalability across large fleets. Even popular open-source solutions like Chrony converge quickly but can’t deliver nanosecond precision or handle hyperscale, multi-cloud environments reliably.
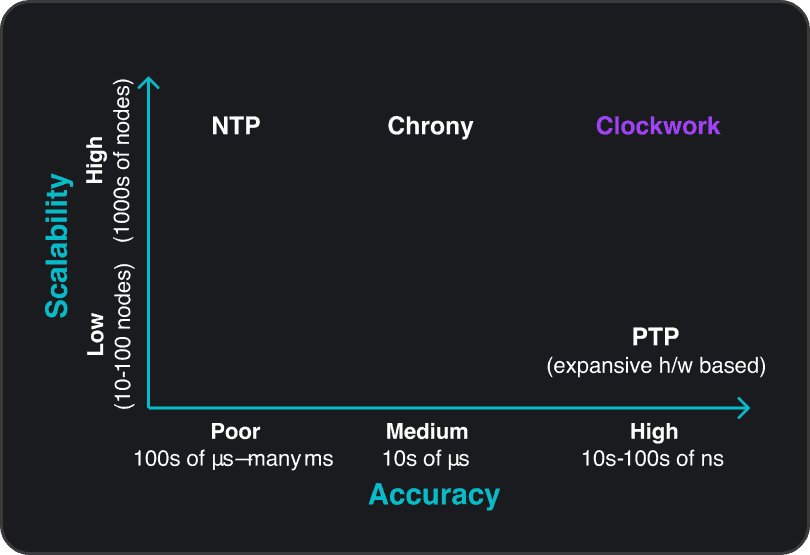
Clockwork Solutions
Clockwork provides the foundation for precision observability at AI scale. By embedding time-aligned telemetry into every layer of the stack, operators gain dual visibility: Provisioning Health – Are racks wired correctly? Is firmware configured and stable? Runtime Efficiency – Which jobs, GPUs, or links are becoming stragglers or outliers? With this visibility, alerts fire at the first sign of trouble—whether link, node, or workload—long before users experience slowdowns.

Clockwork’s Approach: Breakthrough
ClockSync builds on pioneering research published at USENIX NSDI:
“Exploiting a Natural Network Effect for Scalable, Fine-grained Clock Synchronization.”
This work, co-authored by researchers at Stanford University and Google, demonstrated how leveraging inherent network traffic patterns enables precise synchronization at scale—without expensive specialized hardware. Clockwork extends and productizes this innovation for real-world AI fleets.
Learn More
Stop wasting GPU cycles. Start scaling smarter.
Clusters must deliver high uptime while running at maximum efficiency.
Turn your GPU clusters into a competitive advantage—not a cost center.

