

The ridesharing company is the global market share leader in providing a technology platform for transportation services. Over the past few years, Acme has expanded from a fully owned, on‑prem footprint to a hybrid, multi‑cloud estate spanning on‑prem data centers, Oracle Cloud Infrastructure (OCI), and Google Cloud Platform (GCP). That shift brings hardware diversity, cost/performance advantages, and capacity elasticity, but it also creates blind spots in network visibility and control – especially around one‑way delays (OWDs), packet loss, and per-VM and per‑container traffic that directly affect service tail latencies and safe VM/container co‑location.
Ridesharing company and Clockwork have partnered to close the network visibility and control gap through the deployment of Clockwork’s FleetIQ platform. FleetIQ uncovers granular, real-time network metrics and insights to detect and localize anomalies faster; and Clockwork’s software-drive control feeds into Acme’s Repair Engine and Allocation Engine to mitigate anomalies automatically.
Ridesharing Company’s Fleet Monitoring Goals
Ridesharing company’s Container Platform team manages more than 50 compute clusters across multiple regions/zones on both on-prem data centers and cloud providers like Oracle® Cloud and Google Cloud™. Each cluster has around 5,000-7,500 hosts, around 250,000 cores, and around 50,000 pods. They power Acme’s 4,000 services that use around 3 million cores. These services get deployed 100,000 times a day, which results in 1.5 million pod launches a day at the rate of 120-130 pods/second in a single cluster. These clusters power Acme’s service federation layer, Up, which developers use to manage their service lifecycle.
To manage its vast fleet of virtual and physical machines, Acme employs a sophisticated host-level monitoring strategy that moves beyond passive data collection. The metrics gathered are not merely for post-mortem analysis but serve as real-time inputs into automated systems that actively manage resource allocation, workload placement, and performance.
While ridesharing company has strong host‑level metrics, host‑level networking signals and container‑level OWD have been incomplete or unavailable in parts of the fleet. Ridesharing company’s ultimate goals are a reduction in average fault localization time by 50%, from 10 to 5 minutes, and a reduction in average fault mitigation time by ~40%, from 17 to 10 minutes. Some of the challenges Acme wants to address are to:
- Isolate sender vs. receiver stack and in-network problems.
- Pin-point noisy neighbors quickly.
- Detect gray failures when incidents present as p99 latency spikes and “healthy‑but‑unhealthy” paths where packet drops or buffers cause retransmissions without clear host alarms.
- Ensure safe VM co‑location and placement. Acme wants confidence in VM/container co‑location decisions across clouds – requiring accurate topology inference, VM migration detection, and the ability to reserve/enforce bandwidth for critical flows when background traffic surges.
Use-Cases Addressed by Clockwork FleetIQ
The following are some of the core use-cases addressed by Clockwork’s FleetIQ platform within Acme’s Container Platform.
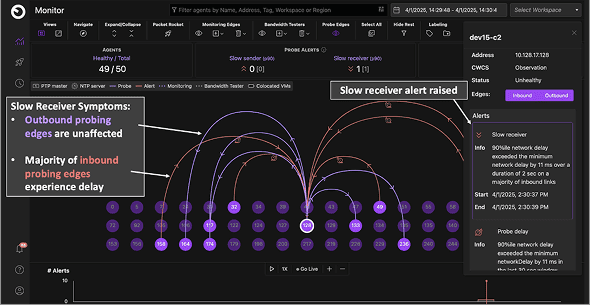
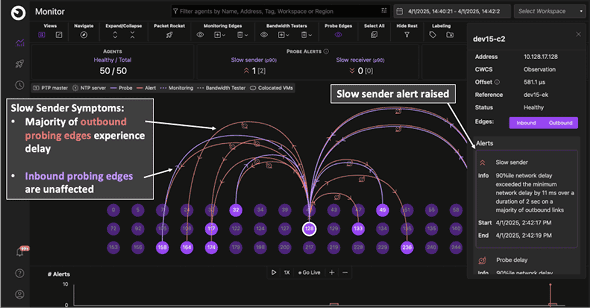
Clockwork’s probe mesh computes one‑way delays along each edge. If most outbound edges from a node degrade, Clockwork raises a slow‑sender alert; if most inbound edges degrade, it raises a slow‑receiver alert—immediately disambiguating node vs. network issues and paging Acme’s Repair Engine.
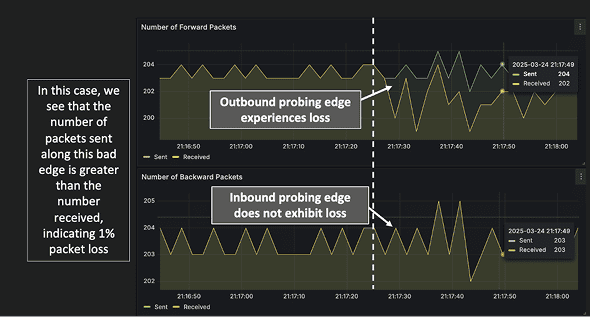
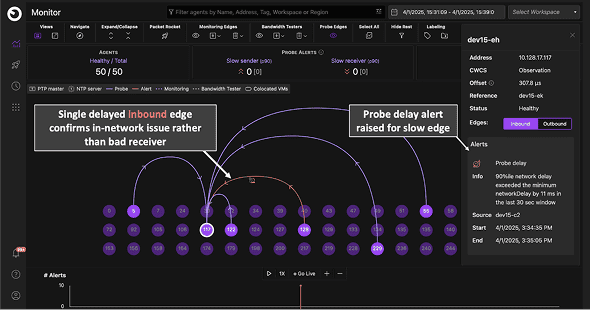
A single delayed or lossy edge (with normal edges elsewhere) indicates an in‑network issue rather than a bad receiver. Edge‑level loss counters (e.g., ~1% loss) plus asymmetric OWDs help Repair Engine localize to links/paths quickly.
Clockwork maps service‑level p99 SLOs to flow‑level OWD SLOs.
- Top-down: When a service violates the p99 latency SLA, Repair Engine queries per‑VM/flow OWDs to localize offenders.
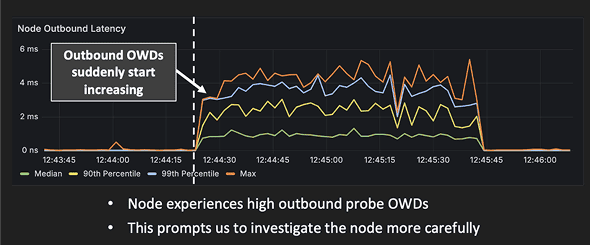
- Bottom-up: Probe and in‑band OWDs themselves trigger alerts, flagging flows and containers causing tail latencies. With synchronized NIC and kernel clocks, Clockwork further segments end‑to‑end latency into sender stack, in‑network, and receiver stack – pinpointing the failing segment.
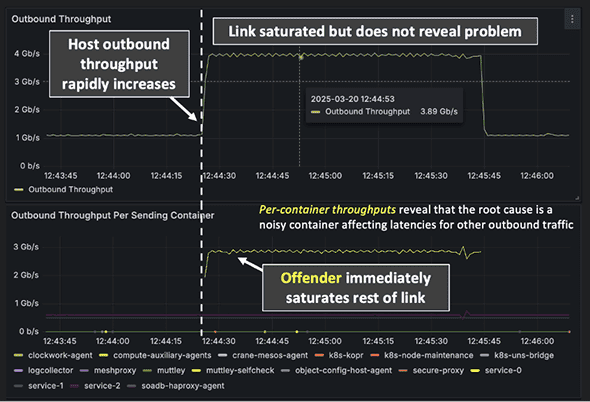
Clockwork’s eBPF (Packet Rocket in telemetry mode) surfaces per‑container throughput and OWD, distinguishing offender from victim containers on a host. In past incidents, node‑level throughput spikes identified the host but masked the specific root cause containers/Pods; per‑container metrics cut straight to root cause, enabling targeted rescheduling.
Clockwork’s clock data detects VM migrations by identifying shifts in a VM’s resonant clock frequency, and the attendant changes in OWDs monitored through the out-of-band probe mesh. Being able to log such events becomes a key input to troubleshooting performance issues during incidents. Structurally, understanding the frequency and pattern of migrations is a key input to Acme’s allocation engine for safe colocation.
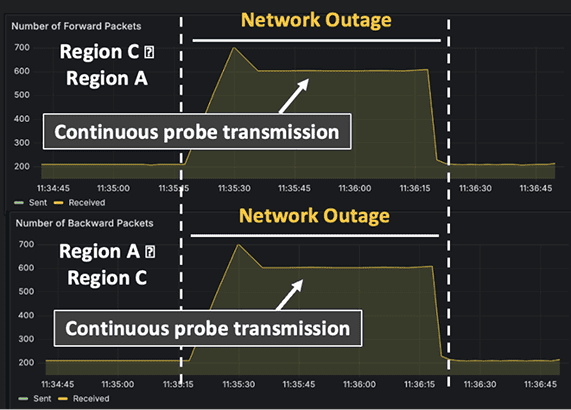
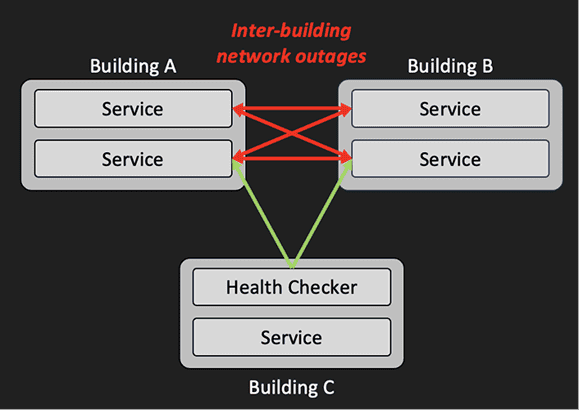
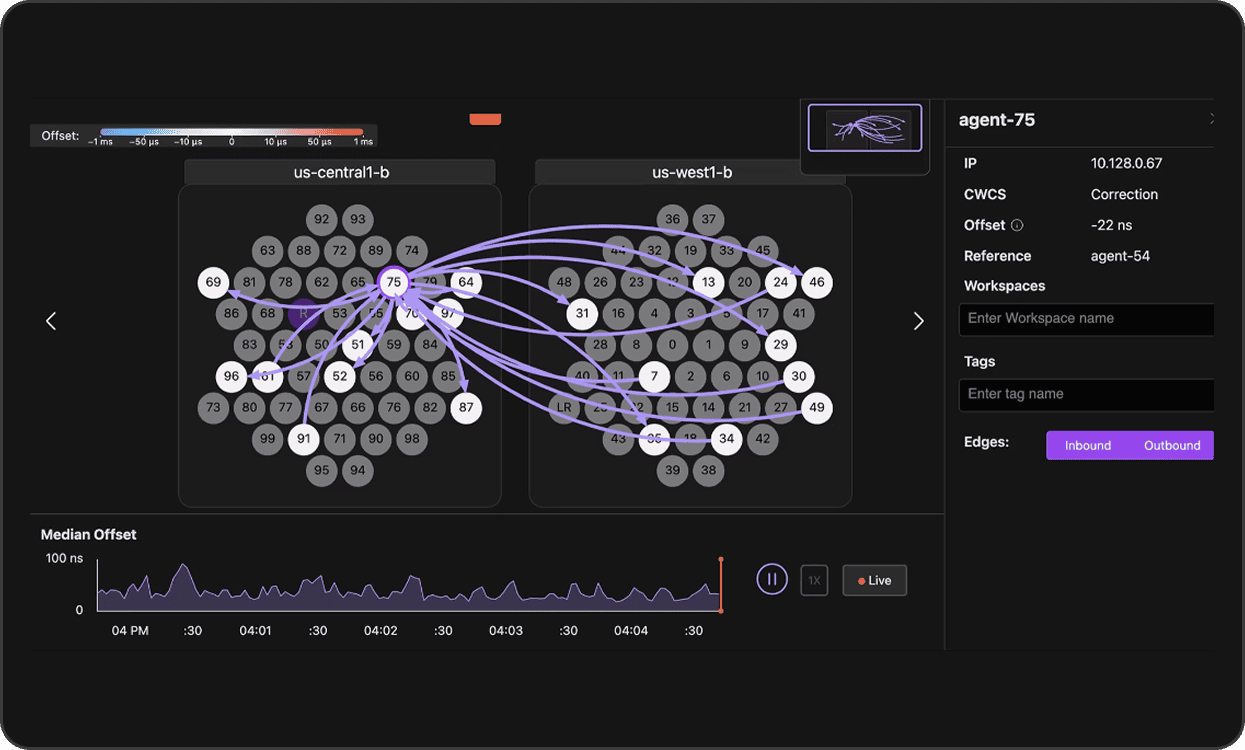
Even when underlying cloud topology is opaque, the probe mesh builds a connectivity map and highlights unhealthy edges (e.g., a building‑to‑building outage). Teams can also add Monitoring Edges to observe specific VM pairs for real‑time debugging with configurable duration and thresholds.

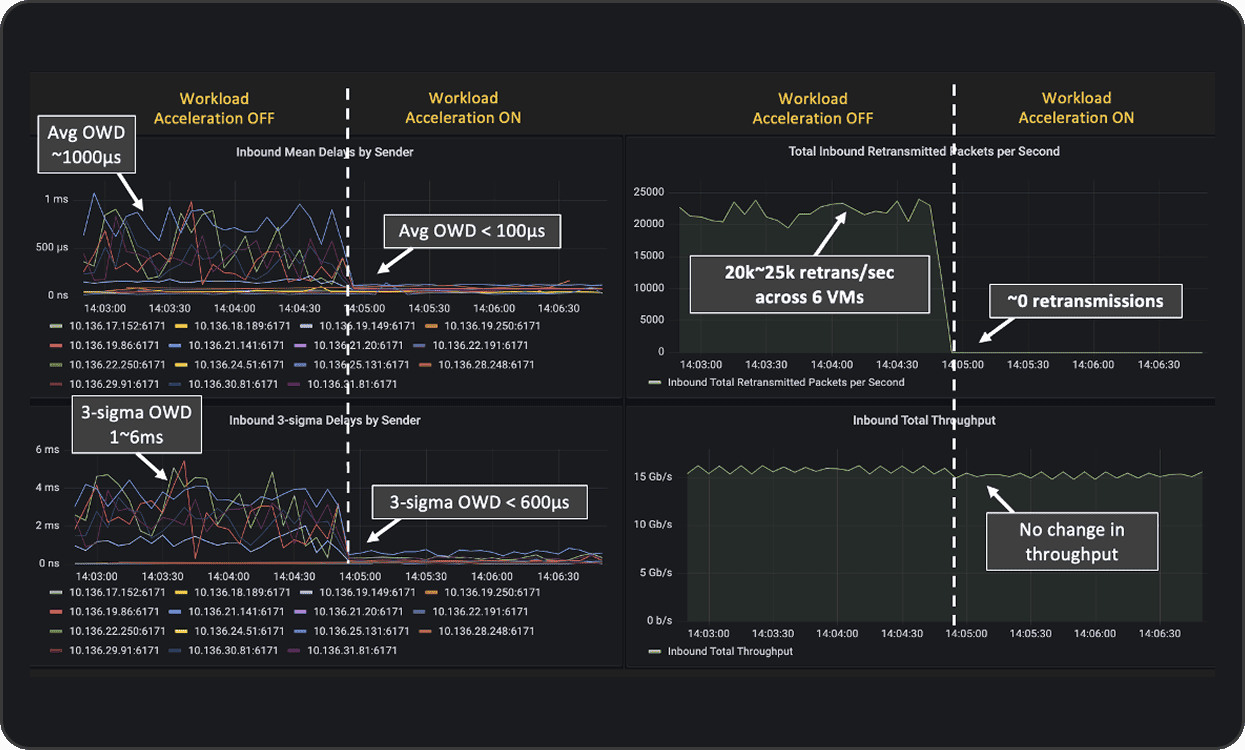
Clockwork detects congestion (rising OWD and retransmissions) and uses FleetIQ’s Workload Acceleration Module to pause senders when OWD crosses thresholds. The result is that drops are eliminated and tail latency is significantly lower. In Acme’s OCI dev zone, enabling Workload Acceleration reduced average OWD from ~1000 µs → <100 µs, cut 3‑sigma OWD from 1–6 ms → <600 µs, and drove retransmissions from ~20–25k/sec → ~0, with no throughput loss.
Bandwidth Slicing is another key feature of Clockwork’s FleetIQ platform, helping to enforce fairness/QoS among competing senders, which Acme’s Allocation Engine can request programmatically.
Delivering Impact at Acme
Acme’s platform has grown into a hybrid, multi‑cloud estate spanning on‑prem data centers, OCI, and GCP. That evolution has delivered elasticity and hardware diversity but also introduced network blind spots that host‑level metrics alone cannot resolve – especially around one‑way latency, gray failures, and per‑container traffic that directly affect tail latencies and safe co‑location. Clockwork closes the network visibility gap with uniform, cross‑cloud observability and control that requires no switch changes, aligning with Acme’s strategy to raise utilization safely by packing more containers and VMs per host while keeping service reliability intact.
Clockwork’s deployment is aimed at compressing Acme’s incident timelines materially. The primary success criteria are straightforward: (i) A decline in mean fault‑localization time – anomaly onset to identification of the specific host, edge, or container – from roughly 10 minutes to ≤ 5 minutes, and (ii) A decline in mean fault‑mitigation time – localization to a successful remedial action such as reschedule, pause, or bandwidth slice – from about 17 minutes to ≤10 minutes. These targets anchor the ROI of the initiative.
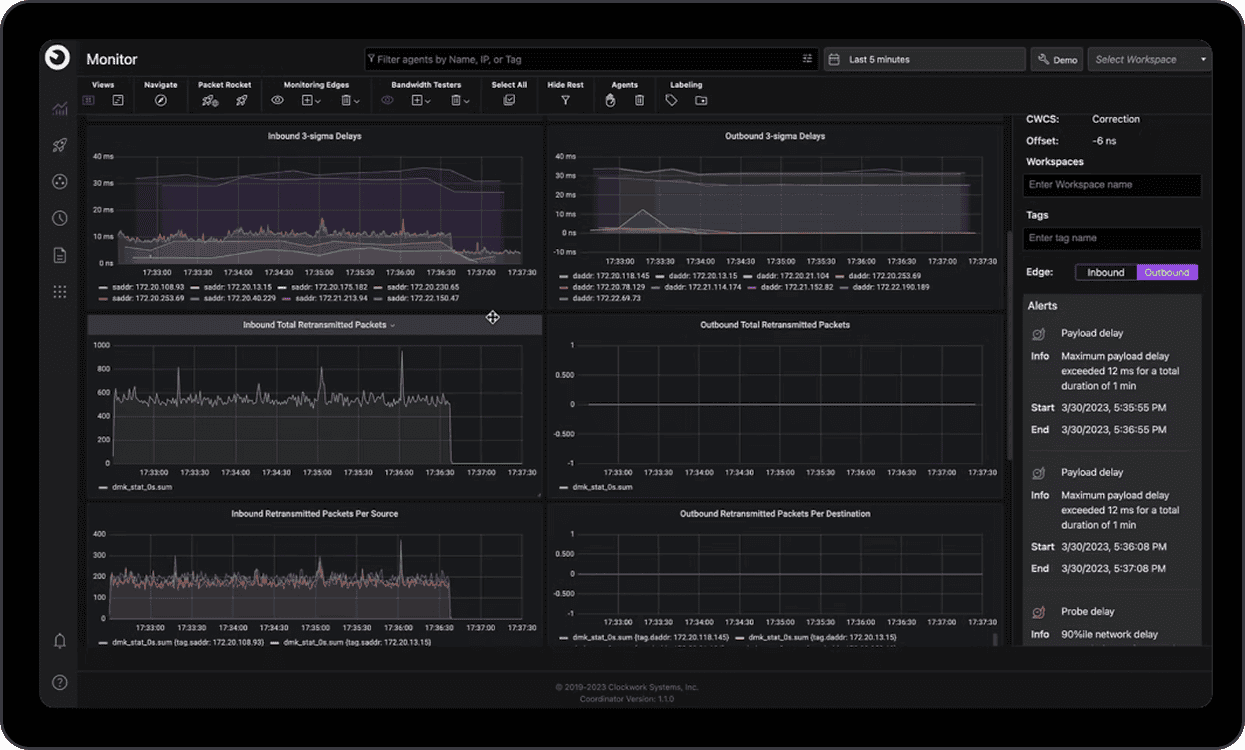
A set of leading indicators that describe both coverage and signal quality are key to tracking roll-out over time. Coverage captures the percentage of the fleet with ClockSync agents active and healthy, and – critically for closed‑loop controls – the percentage of Kubernetes/cgroup v2 nodes with the eBPF module enabled. Signal quality captures the share of probe‑mesh edges sustaining microsecond‑level one‑way‑delay (OWD) accuracy and, on hosts running the in‑band module, the share of flows with per‑container OWD. This instrumentation allows Acme’s Repair Engine to disambiguate slow‑sender, slow‑receiver, and in‑network issues and, when needed, create Monitoring Edges to observe specific pairs for time-bounded investigations.
Acme is also driving for tail‑latency improvements at the service level. Dev‑zone deployments have already shown that turning on the control loop can reduce average OWD by an order of magnitude (from ~1000 µs to <100 µs), cut 3‑sigma OWD from 1–6 ms to <600 µs, and drop retransmissions from ~20–25k/sec to near‑zero without degrading throughput – evidence that the telemetry and controls translate into meaningful application‑level gains.
Clockwork’s Technology
enabling Acme’s use-cases
In highly distributed and demanding workloads, such as AI training and inference and large-scale, latency-sensitive user-facing microservices-based applications, communication is as significant a bottleneck as compute. Effective communication gates overall efficiency, and congested networks with poor visibility can cause operating teams hours of trouble-shooting degraded services.
Clockwork’s vision of a Software-Driven Fabric is to make communication reliable and performant by (1) treating communication as the new Moore’s Law, to measure, predict, and control fabrics in real time; and (2) building this as a software layer that can “Run Anywhere” – across diverse libraries, transports, accelerators, clouds and network vendors. FleetIQ, our Software-Driven Fabric platform, builds on two foundational capabilities that provide unmatched network visibility and accelerate network performance, entirely through software:
Clockwork’s software-based Global ClockSync comprises a lightweight software agent running on the servers being synchronized that together form a light-weight probe mesh. Leveraging novel machine learning algorithms and signal processing techniques, Global Clocksync aligns every host, switch, NIC and SmartNIC to a common timeline with sub-microsecond accuracy, which in turn forms the basis for extremely granular network telemetry. This telemetry forms the foundation for fine-grained, real-time insights into network conditions.
Once the fabric becomes observable, the next leap is active control. Clockwork’s DTC treats the network as programmable, steering traffic dynamically in response to real-time telemetry. DTC can pace or delay packets, and slice and allocate bandwidth for specific flows.
Building on these foundational capabilities, some of the key features of Clockwork’s FleetIQ platform include the following:
Fleet Monitoring for front-end Ethernet networks
Fleeting Monitoring, a key module of our FleetIQ platform, is a fleet‑wide, always‑on network health and topology monitoring system that combines out-of-band network telemetry with in-band workload-aware network telemetry to provide comprehensive visibility.
Out-of-band network telemetry relies on the Clocksync probe mesh and focuses on liveness, reachability, OWD, packet-loss, and gray failures – independent of application traffic. With the probe mesh, each host forms probe edges to a handful of peers (e.g., ~5), which is sufficient to create a fully connected graph in practice. The mesh provides accurate one‑way delays and packet-loss along edges. Clock‑synchronized timestamps enable consistent correlation across machines and administrative domains. With optional NIC‑clock sync, Fleet Monitoring can segment latency by sender stack / network / receiver stack. Teams can add Monitoring Edges to explicitly probe any specific host pair for time‑bounded investigations.
Key outputs include metric dashboards showing OWD distributions, packet-loss metrics and retransmissions, reachability, host liveness, inferred topology signals, network throughput metrics among many others. Alerts can be configured to watch for slow senders (most outbound edges are slow), slow receivers (most inbound edges are slow), and to highlight in‑network issues on any path.
In-band monitoring extends into the data plane by leveraging eBPF. Fleet monitoring measures per‑container OWD and per-container throughput, and learns a container mesh of communicating endpoints, correlating application flows with the probe‑mesh signals. When NIC‑to‑kernel clock sync is enabled, end‑to‑end latency can be segmented into sender stack, in‑network, and receiver stack components, accelerating root‑cause analysis and shrinking the search space during incidents.
FleetIQ’s Fleet Monitoring module combines out‑of‑band and in‑band telemetry provide a coherent, cross‑cloud picture: they localize whether a problem is on the host, on a specific path, or in the application’s own stack—and do so with microsecond‑level timing fidelity.
Workload Acceleration for front-end Ethernet networks
Workload Acceleration, A second key module within Clockwork’s FleetIQ platform, goes beyond monitoring to actively accelerating fleet performance by managing congestion and enabling QoS/bandwidth slicing to manage flow-level contention – two key impediments to workload performance at scale.
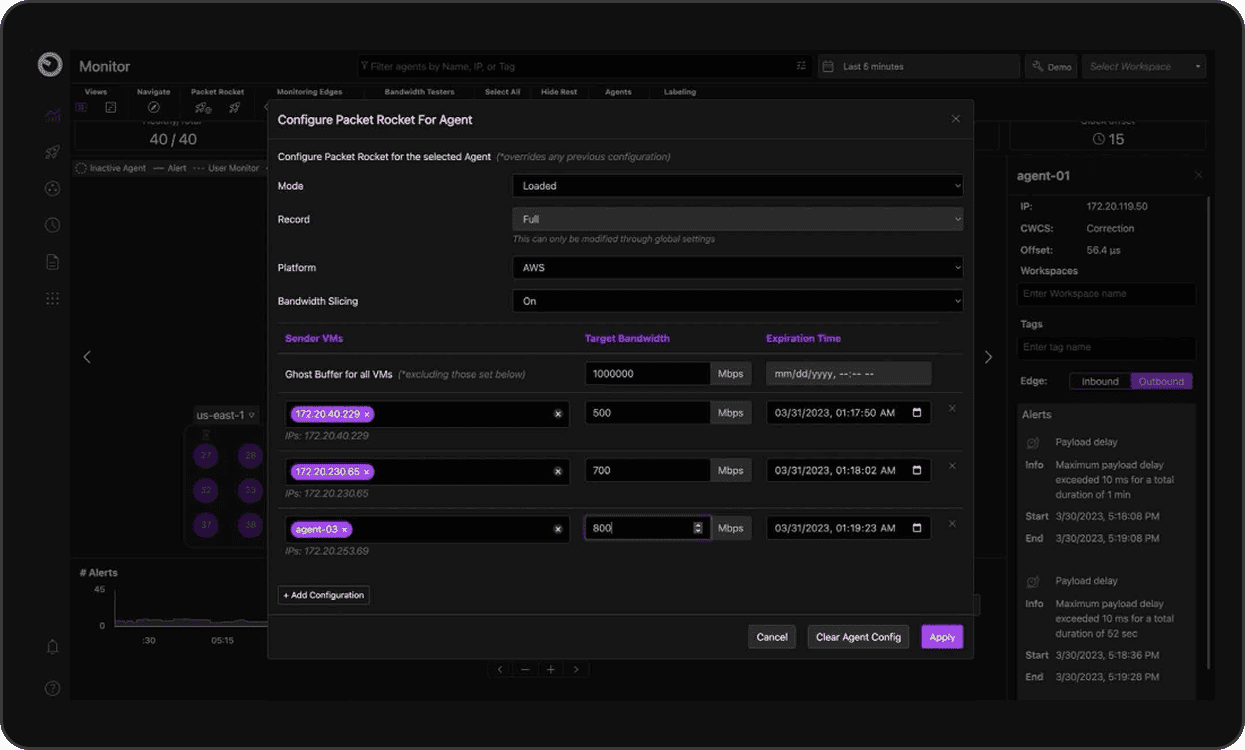
Packet Rocket is a feature of FleetIQ’s Workload Acceleration Module that applies eBPF‑based control loops to watch OWD and throughput on live flows. When OWD crosses a threshold, Packet Rocket software pauses senders adaptively to manage in-network congestion, letting queues drain before traffic resumes. This mechanism suppresses retransmissions and jitter, cuts tail latency, and stabilizes flows without sacrificing sustained throughput. Complementing OWD based pausing, Workload Acceleration also implements pausing based on measured receiver throughput. Operators can configure a bandwidth threshold, named a “Ghost Buffer”, to manage incast congestion such that senders are paused when the throughput at the receiver exceeds the Ghost Buffer – a value that is typically lower than the receiver’s maximum possible line rate.
Because Packet Rocket operates entirely at the host edge and uses synchronized timestamps, it provides vendor‑agnostic congestion control that works consistently across on‑prem data centers and public clouds, even when the network fabric cannot be modified.
Bandwidth Slicing is another key feature of FleetIQ’s Workload Acceleration Module. Bandwidth Slicing carves networks into isolated logical segments – all using software and requiring no hardware functionality. Bandwidth Slicing works by assigning predictable bandwidth shares to senders or flows competing on a link – protecting priority traffic and enforcing fairness without switch‑level configuration. Policies are orchestrated centrally and enforced at hosts, allowing platforms to guarantee minimum throughput for critical applications while preventing background transfers from monopolizing capacity. Slices can be adjusted dynamically at runtime and used alongside Packet Rocket’s congestion controls to keep loss low and latency bounded under load. Because enforcement happens at the edge and is driven by accurate, per‑flow telemetry, Bandwidth Slicing delivers consistent performance isolation across heterogeneous environments, from bare‑metal clusters to multi‑cloud deployments.Bandwidth Slicing guarantees resources for critical workloads, enforcing isolation and performance guarantees on commodity hardware.
Clockwork’s Software‑Driven Fabric is a new foundation for managing infrastructure as the world increasingly embraces highly distributed, demanding workloads whose performance, reliability and efficiency depend on the effectiveness of the underlying network and communication flows.
By fusing nanosecond-level visibility, dynamic traffic control, and job-aware resilience into a single software plane, FleetIQ converts communication from the weakest link into the strongest lever for performance. As workloads become more distributed and scale in urgency and consequence, mastering communication across CPU and GPU hosts, containers, clusters, and clouds is key to delivering infrastructure that is faster, more resilient, and economically sustainable at global scale. Clockwork exists to make that mastery possible and real.
