
It can be easy to forget or take for granted, but the millions of computer servers and billions of connected devices we depend on for so many of our routine activities rely on precise timing and onboard clocks. These onboard clocks have to synchronize with a reference clock over a network in order to help the apps we regularly use to function properly, without hiccups.
The need for time synchronization is a decades-old challenge that predates the Internet and has a long history in fields like radio broadcasting and telecommunications. But the advent of distributed computing and networking and a world now run on apps requires network time synchronization at a scale and level of precision that poses a real challenge to existing time synchronization algorithms.
Time and distributed computing
Distributed applications that operate on a common time axis across many nodes depend on accurately synchronized clocks to achieve consensus among nodes, consistency across databases, and proper ordering of network messages. And in order for distributed databases to perform with high consistency and fidelity, they need to maintain a very small clock uncertainty period. For instance, in the case of CockroachDB, uncertainty in their clocks can cause read retries; a 1 ms to 100 ns reduction in their uncertainty period can result in significant performance improvements.
This direct correlation between uncertainty periods and performance and reliability also applies to distributed tracing. In a microservices architecture, services run across multiple containers in different cloud regions. If time isn’t precisely synchronized with a high level of accuracy, the timestamps used to log various RPCs could mix up the sequence of events (like recording that a child RPC started before its parent). Not only would a situation like this make debugging and profiling more challenging, it would also make it very difficult for a developer to stitch together an accurately ordered timeline of a customer’s journey.
Time and networking
While packet switching offers network efficiency and minimizes latency, it’s also known to result in random packet delays and can’t guarantee performance. To illustrate: Imagine two packets originating from the same transmit server, going to the same receive server, and using the exact same path. While their points of transmission may be identical, their actual transmit times within the network can still differ due to random delays.
Now imagine that packet-switching scenario in the context of a financial trading network, where fairness in trading dictates that all transactions be executed in the order of their arrival times. These financial transactions would arrive at the matching engine through various gateway servers. But jitters within the network and random packet delays could result in a later transaction getting to the matching engine before an earlier transaction, creating out-of-sequence executions.
How computers tell time
Today, most computers use quartz crystal oscillators to keep time, but unfortunately, these clocks are rarely consistent and accurate in their timekeeping. In fact, a clock’s resonant frequency (the rate at which the clock ticks) is only accurate to a few parts per million if it’s maintained within an ideal operating temperature range of 77℉ to 82.4℉ (or 25℃ to 28℃). If the clock’s temperature rises or falls outside of that ideal range due to work loads or other environmental factors, the resonant frequency decreases quadratically. Left unchecked, this can easily lead to seconds of inaccuracy, which can be detrimental in some cases, including the financial transactions scenario we covered earlier.
In addition to keeping time, computer clocks also have to synchronize themselves with a reference clock. Most computer clocks rely on the Network Time Protocol (NTP) to do this. NTP estimates the offset between two clocks by factoring in multiple probe-echo pairs, picking the three pairs with the smallest RTTs, and halving their average. It achieves an accuracy ranging from tens of milliseconds to tens of microseconds. NTP also uses a Stratum model where the Stratum level (0-15) indicates a device’s distance from the reference clock. Stratum 0 is connected to the global navigation satellite system (GNSS). Stratum 1 time servers distribute time to Stratum 2 servers or clients, and so on. To get NTP time on a server, you need to run a daemon that will ping an NTP server periodically and apply corrections locally, as needed.
But there’s more than one clock on your computer
As if time keeping and synchronization didn’t pose enough of a challenge, you also have to consider the fact that your computer doesn’t have just a single clock. It has two.
System clock: The system clock is located on your computer’s motherboard. It’s maintained by the operating system’s kernel and is also known as Software Time. This clock is mainly used to synchronize and schedule tasks and processes that have to do with the OS. For instance, when an application on your computer asks time(), it uses this clock to get the system time from the OS.
NIC clock: The second clock is the PTP Hardware Clock, located on the Network Interface Card (hence, NIC). This clock is considered to be more accurate than the system clock, because it supports hardware timestamping and isn’t susceptible to variable stack latencies. NIC clocks are used to timestamp incoming and outgoing packets. For example, in electronic trading where high-fidelity clocks are a must-have, savvy market participants will use NIC clocks to timestamp their outgoing transactions and incoming market data.
Keeping clocks in sync is a lot harder than you might think
Synchronizing clocks and controlling their accuracy is no easy feat. Under ideal circumstances, you would improve accuracy by adjusting a clock slowly and smoothly by applying small frequency changes. But even in an ideal case, no two clocks are the same, so the sensitivity in adjustments required by one clock would still likely be different from the sensitivity levels required by another to apply appropriate control.
Here are some factors that make clock synchronization challenging:
Different temperature responses: Clocks exhibit different responses to changing temperatures based on the hardware manufacturing processes used, as well as the quality and dimensions of their crystals.
Different control responsiveness: Because some quartz crystals allow for fine-grain control and some don’t, it isn’t possible for a clock controller to apply controls uniformly across all clocks. Instead, the controller needs to be an adaptive system with a real-time feedback loop and the ability to make finer adjustments continuously.
Nonlinear clock drift: While some variables like temperature can cause clocks to slowly change over time, there are also variables like the heating and cooling of crystals that can cause nonlinear changes on the order of minutes.
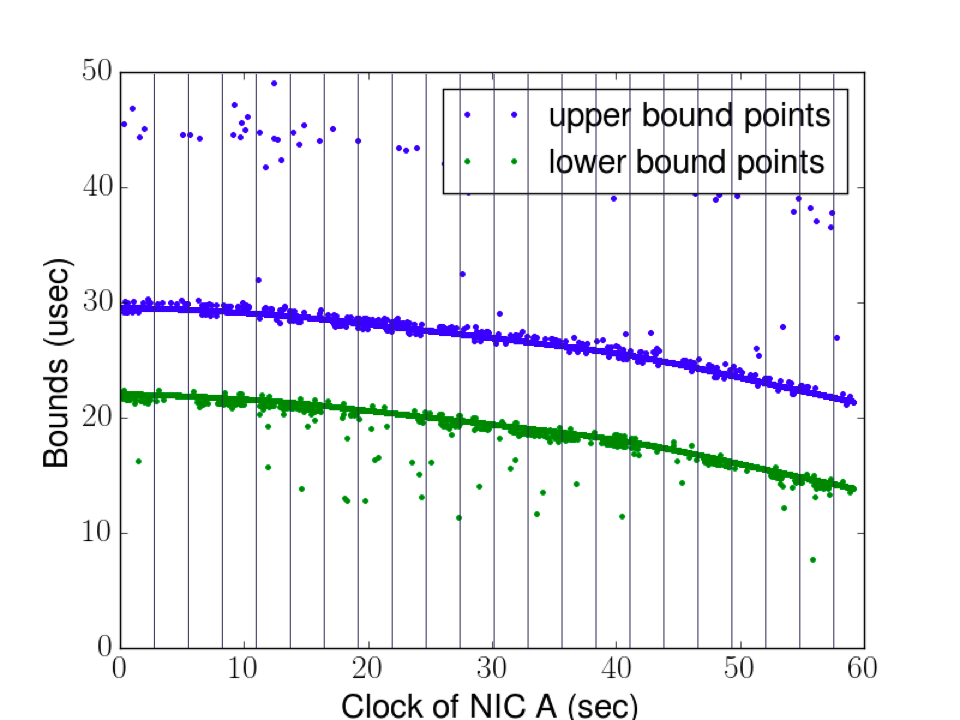
An example of nonlinear drift taken from a NIC clock
Clocks gone wild
When clocks aren’t well synchronized, they don’t just remain out of sync — they actually drift away from each other, temporally speaking. To illustrate, below is a histogram of drifts between pairs of clocks within a data center. While a typical drift can be anywhere between 6 to 10 us/sec, the worst offenders can drift as high as 30 us/sec — all measured against the network reference clock. According to their timestamps, some packets may appear to arrive even before they’ve left their transmit servers, which obviously can’t be true.
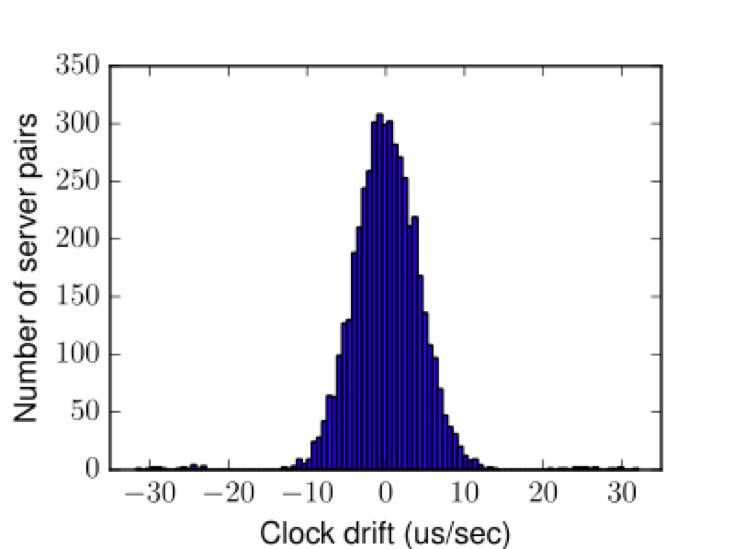
A histogram of drifts between pairs of clocks within a data center, some pairs drift as high as 30 us/sec
When clocks aren’t properly synchronized, one-way delay measurements within a distributed system are useless. For example, if you’re someone who maintains a distributed system, you might see the minimum one-way delay curves oscillate, become negative, and/or drift away.
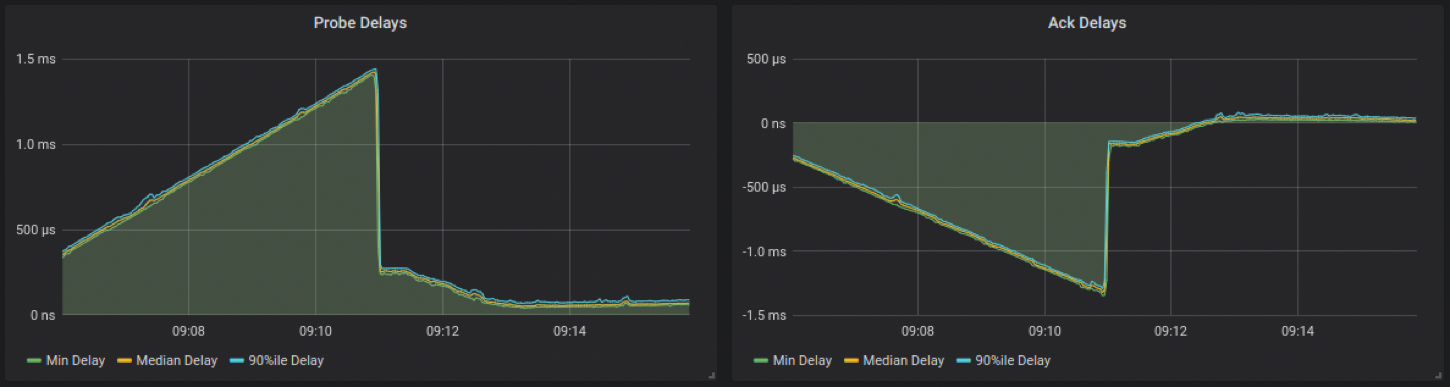
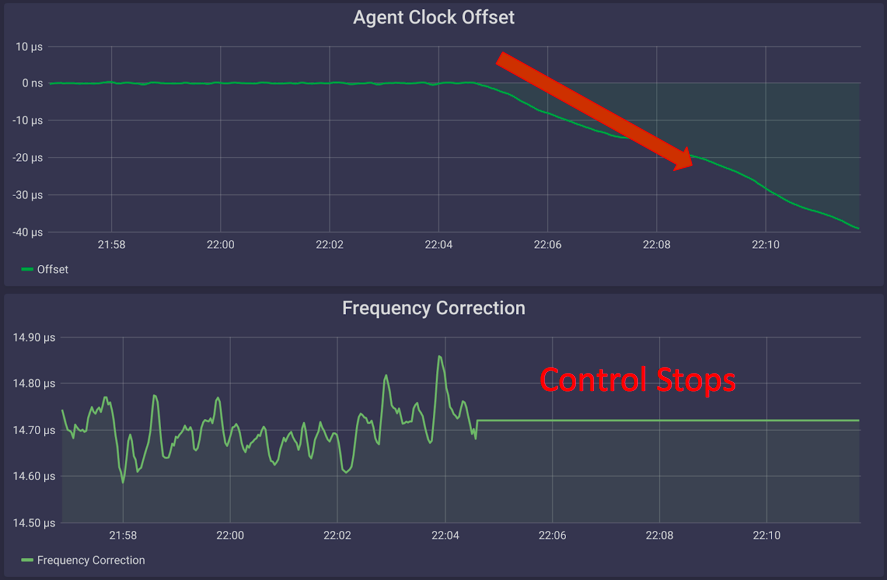
You might have guessed by now, but controlling clocks isn’t a 9-to-5 job — it’s an always-on, 24/7, around-the-clock job, because when a clock controller stops applying corrections, clocks tend to run wild. In the example below, you can see that Clock 1’s frequency begins to jitter around its mean frequency when control is stopped.
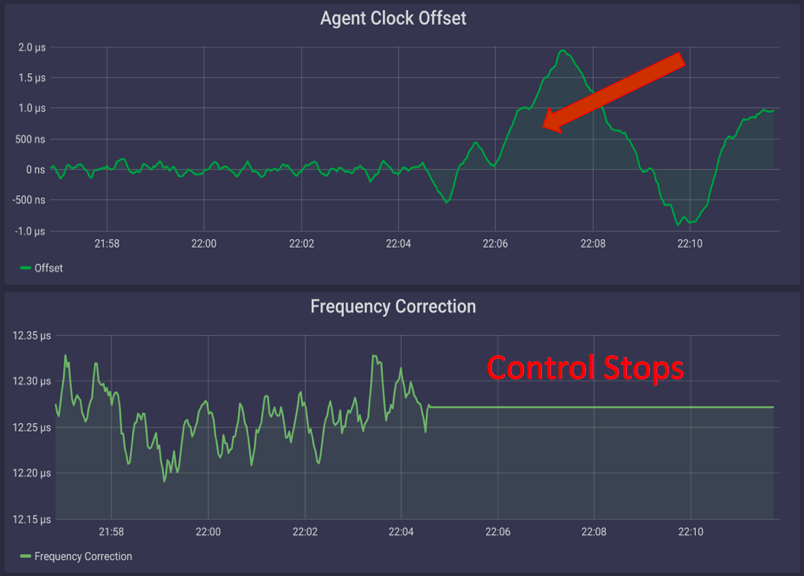
Meanwhile, Clock 2’s mean frequency deviates from the reference and continues to drift away.
The holy grail: A cloud-based, high-accuracy time synchronization system that’s designed for scale
Although the widely used NTP protocol can achieve 100s of microseconds to a few milliseconds of accuracy, that accuracy is no longer sufficient for today’s real-time, distributed applications. Because of this, some financial services firms have turned to hardware-based solutions that use PTP (Precision Time Protocol) and PPS (Pulse per Second), which are expensive to deploy and challenging to maintain. PTP and PPS both also have some fundamental limitations that prevent them from scaling for more than a few hundred nodes.
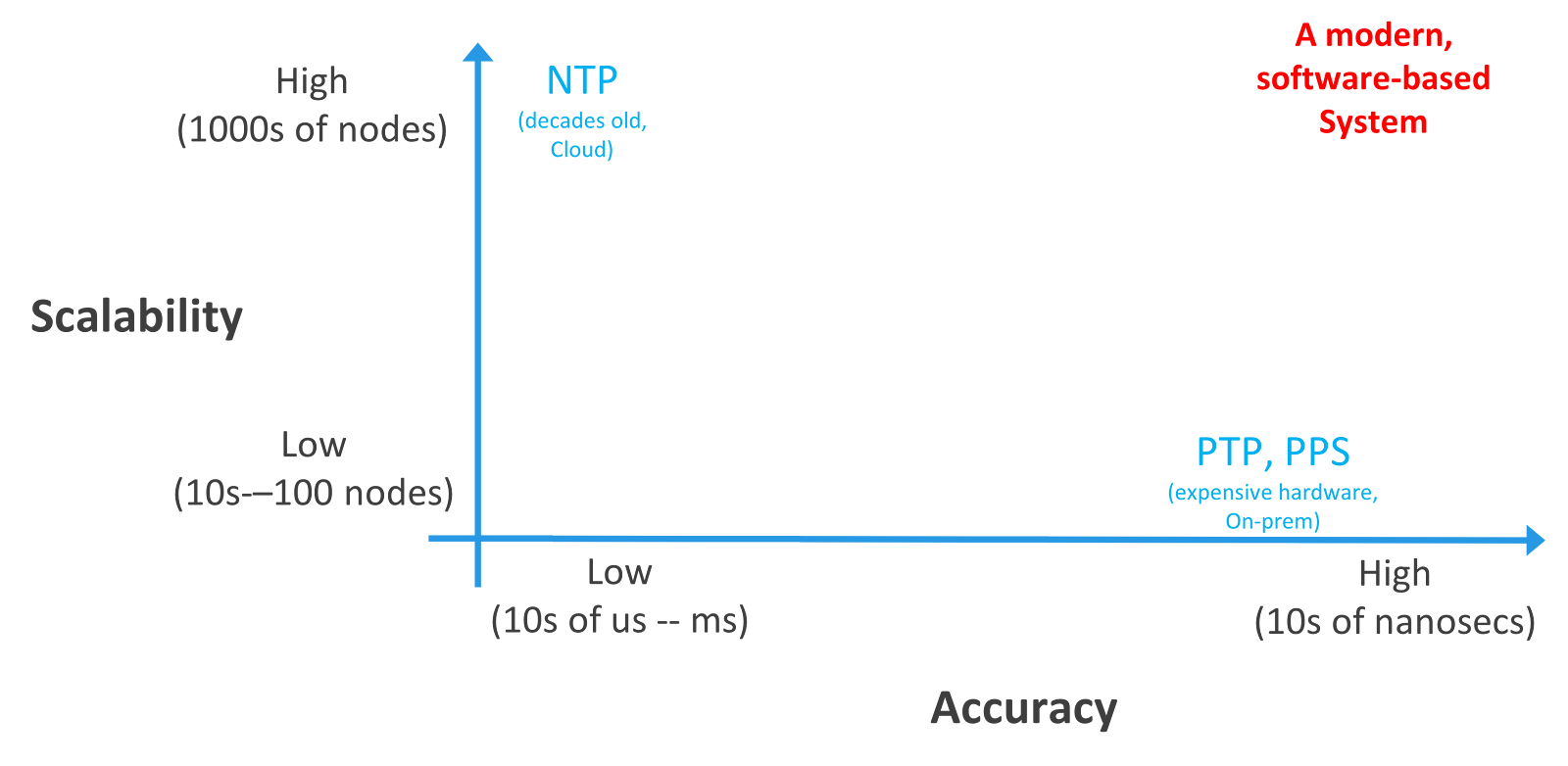
By now, it should be pretty clear that high-fidelity time synchronization is mission critical to both computing and networking. Accurate clock syncing can you take you from batch processing to real-time processing with high throughput, and best-effort packet-switching to a network that’s deterministic and low latency.
At Tick Tock Networks, we think it’s about time businesses had a modern, reliable time synchronization system that can run on commodity hardware across on-prem, cloud, and hybrid environments.