AI that never stalls.
GPUs that never sit idle.
Clockwork’s software-driven AI fabric maximizes GPU utilization and makes AI workloads resilient to failure. Runs anywhere and supports any Ethernet, RoCE or InfiniBand fabric.
Software Driven AI Fabrics Drive
Peak Cluster Utilization
AI Observability
identify slow or failing jobs correlated with infrastructure issues
AI Fault Tolerance
avoid costly checkpoint restarts and run nonstop AI jobs
AI Performance Optimization
eliminate contention, congestion and guarantee performance

SemiAnalysis Confirms Clockwork TorchPass Is the Only Fault-Tolerance Framework That Doesn’t Cost You Training Performance
Their report’s TCO and Goodput calculators demonstrate TorchPass outperforms every competing fault-tolerance approach, recovering millions in wasted compute annually.
Customer and Industry Voices
The Bottleneck in AI is Communication, Not Compute
AI at scale relies on tightly synchronized workloads across complex infrastructures. Performance is not limited by how fast each GPU is, but by how fast thousands of GPUs can talk to each other.
Network Communications
Utilization
Even the smallest disruption causes entire jobs to fail, wasting hours of expensive GPU time.

Stringent I/O demand

Synchronized, stateful flows

Multiple complex fabrics

Frequent failures
Software Driven AI Fabrics Eliminate
The Communication Bottleneck
Performance is accelerated by optimizing traffic flow, and workloads keep running
even when failures occur, preventing expensive checkpoint rollbacks.
FleetIQ runs your AI workloads at peak cluster utilization.

AI Observability
Identify slow, inefficient or failing workloads and see how they’re correlated with infrastructure issues.

AI Fault Tolerance
Avoid costly checkpoint restarts. Keep AI workloads running even when underlying infrastructure fails.

AI Performance Optimization
Dynamically eliminate congestion and contention. Guarantee performance with QoS.
Prevent Link Flaps and GPU Failures From Crashing your Jobs
Failure in Brand New Cluster
In GPU clusters, link flaps, GPU failures, driver or firmware bugs and node failures can crash critical AI jobs in an instant. TorchPass workload fault tolerance makes those failures irrelevant through live workload migration and path failover. Watch how Clockwork keeps everything running even when things fail.
SemiAnalysis Quantifies the Value of Fault-Tolerance
At scale, the choice of fault-tolerance framework is a direct driver of GPU utilization and TCO. This webinar, co-presented by Clockwork.io and SemiAnalysis, benchmarks leading resiliency frameworks — and TorchPass wins decisively, with the ClusterMAX TCO and Goodput calculators showing exactly what that gap costs in dollars.
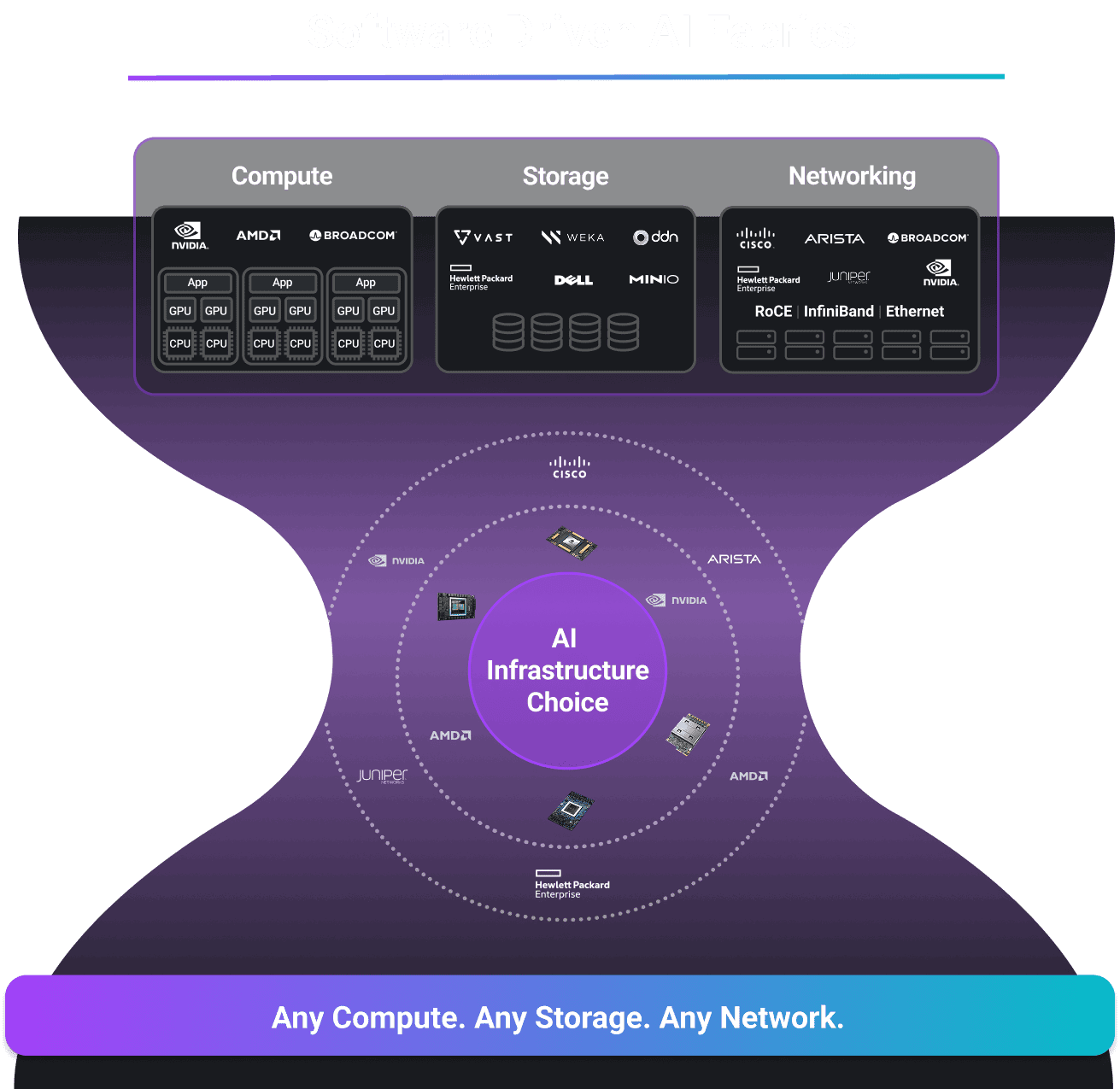
For Multi-vendor Compute, Storage and Networks
Clockwork’s software-driven AI fabric runs anywhere – cloud or on-prem, NVIDIA or AMD, InfiniBand/RoCE or Ethernet, NVMe or object storage. It continuously optimizes your AI infrastructure, steering traffic to prevent congestion and dynamically routing around faults to keep workloads from crashing. Stop wasting GPU cycles – your most valuable and expensive resource.
Explainer Videos: Software Driven AI Fabrics
Optimize Cluster Utilization

Learn More
Stop wasting GPU cycles. Start scaling smarter.
Clusters must deliver high uptime while running at maximum efficiency.
Turn your GPU clusters into a competitive advantage—not a cost center.

