Accelerate AI Around The Clock.
AI that never stalls. GPUs that never sit idle. Clockwork’s hardware-agnostic Software Driven Fabric keeps workloads crash-proof, accelerated, and GPUs fully utilized—at any scale
No crashes. No slowdowns. Just efficient speed-to-market.
“As AI infrastructure scales to tens of thousands of GPUs for training and inference, the bottleneck has shifted from compute to communication. With accelerators running in lockstep, a single link flap, congestion spike or straggler can stall progress and crater utilization. The operational priority is utilizing real-time fabric visibility for faster fault isolation and recovery to keep workloads moving instead of looping through costly restarts. And as Mixture of Experts (MoE) models with high rank expert parallelism proliferate, the all-to-all exchange intensifies, raising the bar even higher for GPU communication efficiency.”

Clockwork Launches FleetIQ to Recast GPU Economics, Appoints Suresh Vasudevan as CEO
Uber accelerates incident detection, DCAI drives faster AI training and cluster efficiency, and Nebius raises MTBF in large-scale distributed AI—all powered by Clockwork’s first-of-its-kind Software-Driven Fabric.
Customer and Industry Voices

Compute Isn’t The Bottleneck. Communication Is.
Convert Idle GPUs into Productive Intelligence
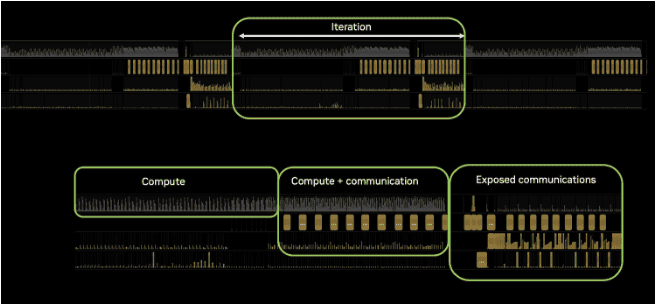
GPU clusters deliver 30–55% of peak capacity—wasting billions at scale. GPUs should be busy processing AI workloads—but instead, they sit idle waiting on the network.
18–57% of training and 40–75% of inference time (AMD) is lost to communication, turning even small hiccups like link flaps into costly restarts and wasted GPU hours.

The result: an AI efficiency gap caused by three compounding issues—visibility (pinpointing slowdowns), reliability (frequent cluster failures), and performance (traffic collisions and congestion).
Clockwork closes this gap. Our hardware-agnostic software fabric delivers nanosecond-precise visibility, dynamic traffic control, and job-aware resilience, so AI jobs run through failures, GPU utilization rises, and stranded capacity becomes dependable power—at scale.

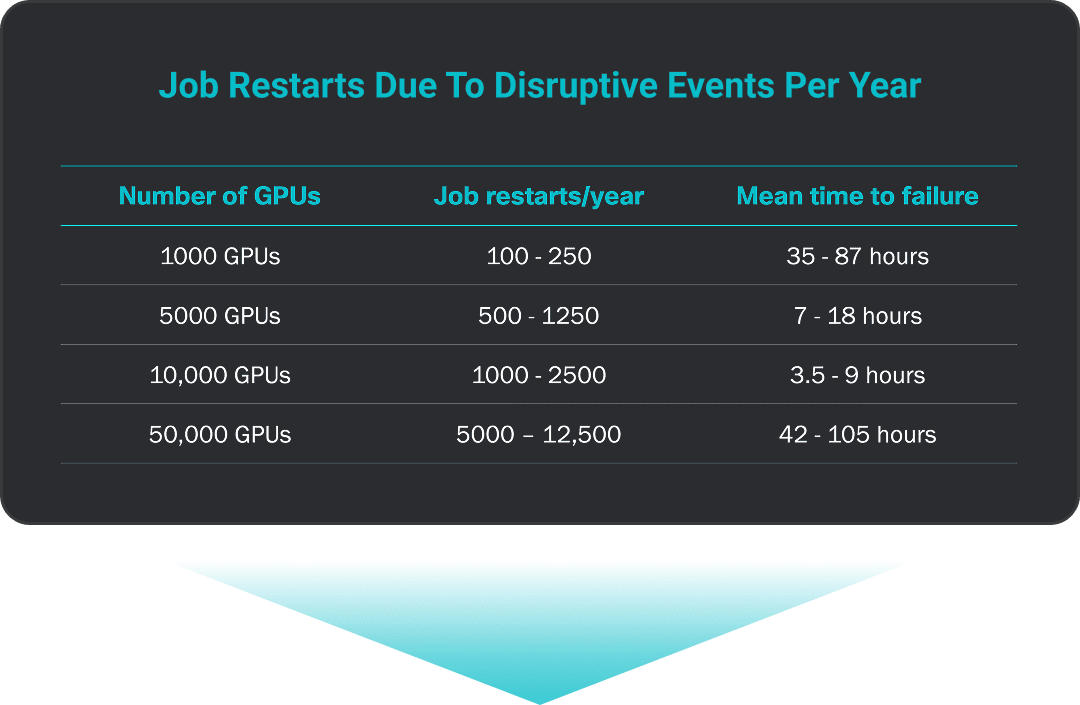
“Achieving high utilization with them (GPUs) is difficult due to the high failure rate of various components, especially networking.
See AI Jobs Run Through the Failures That Break Others
In GPU clusters, network link failures are constant—and they can crash critical AI jobs in an instant. Clockwork makes those failures irrelevant. Watch how our software fabric keeps jobs running, uninterrupted, even when a live network cable is pulled.
“All cloud providers and infrastructure teams have these problems. These are important problems to solve.”


AI Training Communication Constraints
Of AI Training and Inference Time
is Spent on Network Communications

Time to First Job Failure in Brand
New Cluster

Of GPU Potential Capacity is Wasted in
Real-world Clusters
AI Training and Inference

Stringent I/O demand
Lossless, TB-bandwidth, microsecond latency

Synchronized, stateful flows
Application, GPU-to-GPU, storage I/O flows

Multiple networks / transports
Ethernet, ROCE and InfiniBand

Frequent hardware failures
Jobs forced to restart too often
Clockwork Software Driven Fabric
Optimizes Cluster Utilization
AI Training and Inference

Cross-stack visibility
Identify WHY jobs are slow, inefficient or failing and correlate with underlying infrastructure issues.

Stateful fault-tolerance
Jobs should continue without disruptions despite infrastructure failures

Efficient performance
Eliminate congestion, contention and infrastructure bottlenecks
Explainer Videos: Software Driven Fabrics
Optimize Cluster Utilization
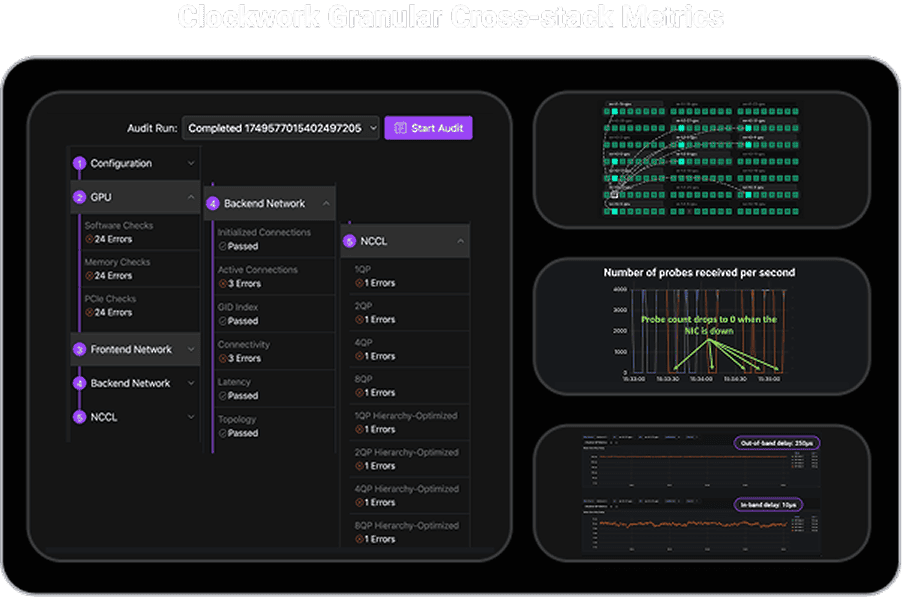
For Multi-vendor Accelerators and Networks
Clockwork’s breakthrough software eliminates the need for expensive, proprietary hardware, enabling hosts to rapidly detect and resolve congestion and network contention. It delivers reliability, acceleration, and full visibility into workload and network health to keep AI jobs running around the clock.
Learn More
Stop wasting GPU cycles. Start scaling smarter.
Clusters must deliver high uptime while running at maximum efficiency.
Turn your GPU clusters into a competitive advantage—not a cost center.

